A estruturação de projetos Go pode representar um desafio, especialmente devido à ausência de padrões rígidos ou convenções oficiais. Essa flexibilidade proporciona autonomia ao desenvolvedor, mas também exige atenção e cuidado para garantir clareza e manutenção eficiente do código.
Este artigo apresenta diretrizes amplamente reconhecidas pela comunidade Go, com o objetivo de auxiliar na organização de projetos.
Project-layout
Um dos modelos mais adotados é o proposto pelo repositório https://github.com/golang-standards/project-layout, que sugere uma estrutura de diretórios em alto nível, baseada em práticas consolidadas de projetos reais.
Alguns dos diretórios recomendados são:
/cmd – Contém os arquivos principais da aplicação, como main.go. Cada subdiretório deve corresponder ao nome do executável. A função main deve ser concisa, delegando responsabilidades para pacotes internos.
/internal – Abriga o código privado da aplicação, não acessível por outros projetos. A partir do Go 1.4, o compilador restringe a importação de pacotes fora da árvore de diretórios.
/pkg – Reúne código que pode ser reutilizado por aplicações externas e por isso o código presente deve ser bem consistente para evitar erros em quem utiliza.
/api – Armazena documentação e definições de APIs, como arquivos Swagger, esquemas JSON e protocolos.
/web – Contém recursos para aplicações web, como arquivos estáticos e templates.
/configs – Inclui arquivos de configuração, como parâmetros de servidor, banco de dados e chaves de API.
/build – Define instruções de compilação e implantação, incluindo Dockerfiles e configurações de integração contínua.
/tools – Reúne ferramentas auxiliares utilizadas no projeto.
/test – Contém dados e funções de apoio para testes de integração. Os testes unitários devem permanecer no mesmo pacote das funções testadas.
⚠️ Recomenda-se evitar o uso do diretório /src, por tratar-se de uma convenção oriunda da linguagem Java, não alinhada às práticas do Go.
Organização de pacotes
A linguagem Go não adota o conceito de subpacotes. Dessa forma, a organização dos pacotes deve ser orientada à clareza e à funcionalidade, facilitando a compreensão por outros desenvolvedores. Por exemplo:
Evite a criação excessiva de pacotes nas fases iniciais do projeto. Uma estrutura simples e contextual tende a ser mais eficaz.
Reduza ao máximo a exposição de tipos e funções exportáveis. Essa prática minimiza o acoplamento entre pacotes e facilita futuras refatorações.
Em caso de dúvida sobre a necessidade de exportação de um elemento, opte por mantê-lo privado.
Nomeie os pacotes com base no que eles oferecem, e não apenas no conteúdo que armazenam. Isso contribui para uma nomenclatura mais intuitiva, sempre lembrando que o nome do pacote é utilizado no uso de um elemento exportado, como:
Parâmetros opcionais são argumentos que não precisam ser fornecidos ao chamar uma função. Eles possuem valores padrão que são utilizados quando nenhum valor é passado, trazendo flexibilidade ao código.
Diferente de linguagens como Python e PHP, o Go não oferece suporte nativo a parâmetros opcionais.
Para se obter esse comportamento no Go, apresento três soluções.
1. Struct de parâmetros
A primeira abordagem é utilizar structs para encapsular os parâmetros opcionais, enquanto os obrigatórios permanecem na assinatura da função:
type Config struct {
Port int
}
func NewServer(addr string, cfg Config) {
}
Essa técnica facilita a adição de novos parâmetros sem quebrar a compatibilidade com chamadas existentes.
Entretanto, é importante lembrar que quando criamos uma struct sem passar valores para seus campos, eles são inicializados com seus zero values:
0 para inteiros
0.0 para floats
"" para strings
nil para slices, maps, channels, ponteiros, interfaces e funções
Se for necessário distinguir entre um valor 0 em um inteiro passado pelo cliente e o zero value do tipo, pode-se usar ponteiros, pois seu zero value será nil.
type Config struct {
Port *int
}
Apesar de funcional, essa abordagem exige a criação explícita de variáveis para referência:
port := 0
config := httplib.Config{
Port: &port,
}
Outro ponto de atenção ao ponteiro é que se ele não for bem tratado existe o risco do programa gerar um panic por nil pointerexception.
Outro ponto negativo de utilizar uma struct como parâmetro opcional é que, se esse parâmetro não for utilizado, ainda será necessário passar uma struct vazia na chamada da função:
httplib.NewServer("localhost", httplib.Config{})
11. Builder
O padrão de projeto Builder delega a criação e validação da struct Config para uma struct intermediária ConfigBuilder, que expõe métodos para configurar os campos:
type ConfigBuilder struct {
port *int
}
func (b *ConfigBuilder) Port(port int) *ConfigBuilder {
b.port = &port
return b
}
func (b *ConfigBuilder) Build() (Config, error) {
// lógica de validação e preenchimento
}
Embora o Go não ofereça suporte nativo a parâmetros opcionais, existem padrões eficazes para contornar essa limitação, como o uso de structs, builders e funções variádicas. A escolha da abordagem ideal depende da complexidade da configuração, da necessidade de validação e da escalabilidade do código.
Referência: HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
Ao criar structs em Go, é possível incorporar outras structs para compor seus campos. Essa técnica permite reutilizar structs e promover seus métodos e atributos, mas exige cuidado.
Para incorporar uma struct, basta declará-la como campo de outra struct sem nomear o tipo, como no exemplo abaixo:
type Foo struct {
Bar
}
type Bar struct {
Baz int
}
Nesse caso, Bar é um embedded type de Foo. Com isso, os campos de Bar podem ser acessados diretamente por Foo de duas formas:
Direta: Foo.Baz = 45
Indireta: Foo.Bar.Baz = 51
A técnica também se aplica a interfaces. Veja o exemplo do pacote io, nativo do Go:
type ReadWriter interface {
Reader
Writer
}
Aqui, ReadWriter é uma composição das interfaces Reader e Writer. Para implementá-la, uma struct precisa implementar os métodos de ambas:
Generics são um recurso que permite escrever funções e estruturas de dados que funcionam com qualquer tipo, garantindo reutilização de código e segurança de tipos em tempo de compilação.
Esse recurso difere do uso dos tipos any/interface{} em Go, que aceitam valores de qualquer tipo, mas sem validação em tempo de compilação. Nesse caso, a verificação ocorre apenas em tempo de execução, o que aumenta o risco de erros inesperados durante a execução do programa.
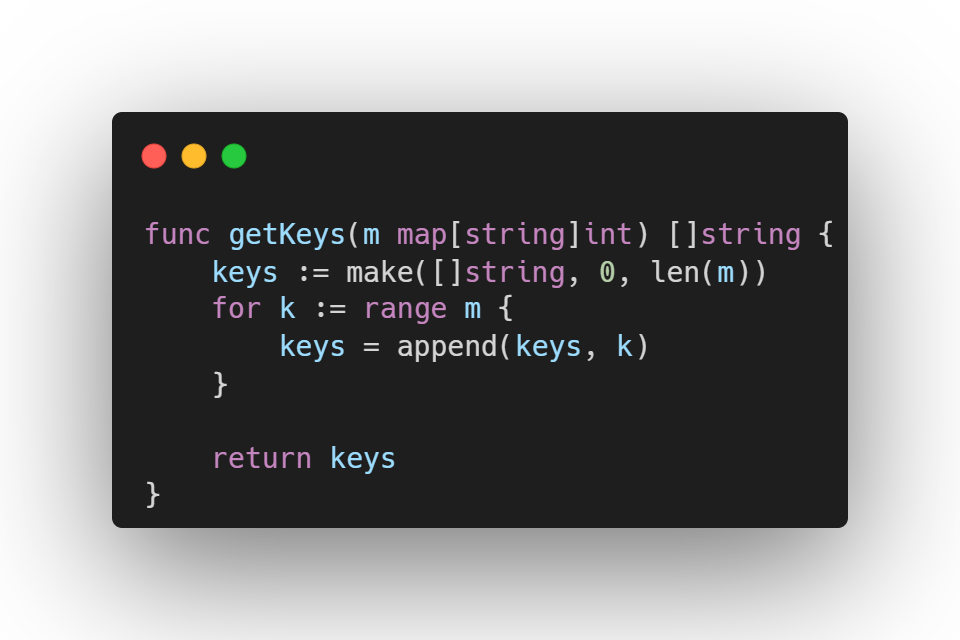
Para exemplificar, vamos criar uma função que recebe um map como parâmetro e retorna um slice contendo suas chaves:
Porém, o tipo da chave está fixado como string. Se precisarmos realizar a mesma operação para um map[int], uma das opções não recomendadas seria duplicar o código e utilizar any nos parâmetros de entrada e saída.
Essa solução escala mal, pois, se for necessário adicionar mais um tipo, será preciso duplicar ainda mais o código do laço for.
Outro ponto de falha é o uso de any, que elimina um dos principais benefícios do Go: ser uma linguagem fortemente tipada. Nesse caso, a função pode ser chamada com qualquer tipo de variável e eventuais erros só serão detectados em tempo de execução, quando a função retornar um resultado inesperado.
Por não conhecermos o tipo do parâmetro de entrada, somos obrigados a retornar um slice de any, que terá que ser tratado pelo código que chama a função. Isso pode causar erros e aumentar o custo de processamento, devido à necessidade de realizar type assertion, ou seja, extrair o valor do any e convertê-lo para seu tipo original.
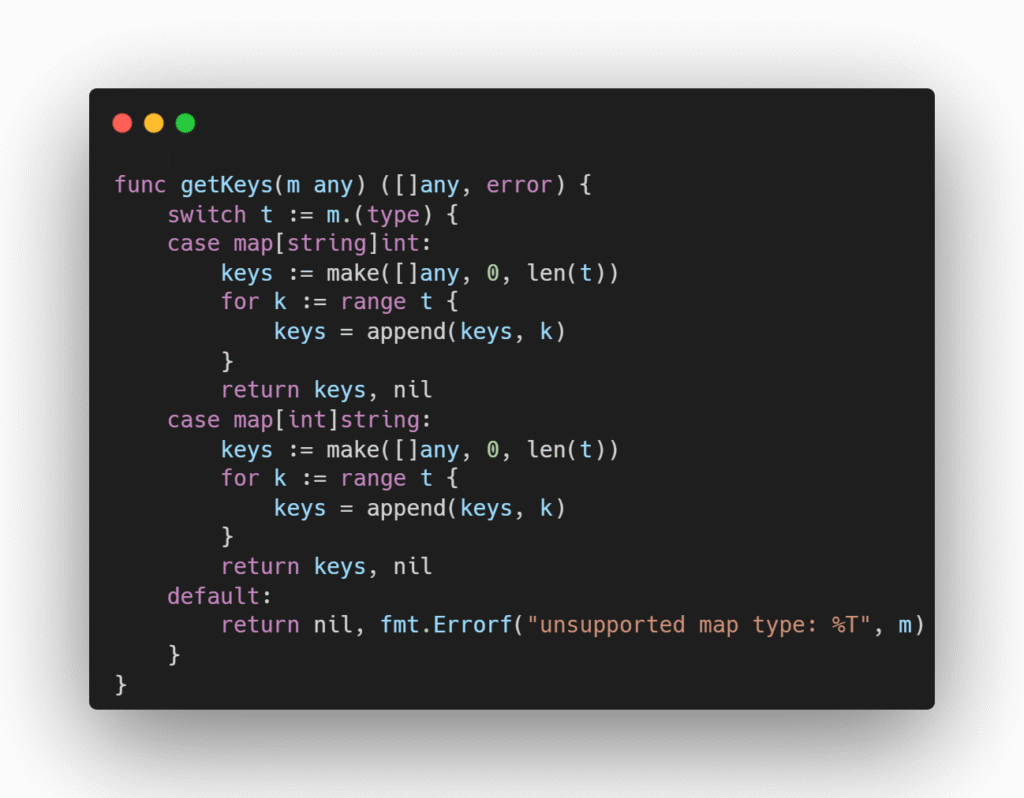
Esse problema é resolvido com os generics. Na sua estrutura, é necessário definir um parâmetro de tipo junto à declaração do nome da função, como visto abaixo na função Filter.
Agora, vamos refatorar nosso código que extrai as chaves de um map.
O primeiro ponto de atenção é que não é possível criar um mapa com chaves de qualquer tipo. É obrigatório que o tipo da chave seja comparável, ou seja, que suporte as operações == e !=.
Por esse motivo, utilizamos o tipo comparable na refatoração, caso contrário teremos o erro invalid map key type K (missing comparable constraint).
Outra possibilidade é criar restrições de tipo para os generics, como mostrado no exemplo abaixo.
Se tentarmos utilizar a função com um map[float64]string, por exemplo, o erro float64 does not satisfy typeConstraint (float64 missing in int | ~string) será exibido durante a compilação.
Observando a typeConstraint, foi definido ~string em vez de apenas string. O til (~) indica que, nessa restrição, é possível utilizar tipos personalizados baseados em string, como mostrado a seguir. Já o int sem o til permite apenas variáveis do tipo int.
Se o til for removido, ocorrerá o erro Foo does not satisfy typeConstraint (possibly missing ~ for string in typeConstraint) em tempo de compilação.
Outra utilização dos generics é com structs, especialmente quando é necessário criar estruturas de dados como filas, pilhas ou até árvores. No exemplo abaixo, é criada uma pilha genérica:
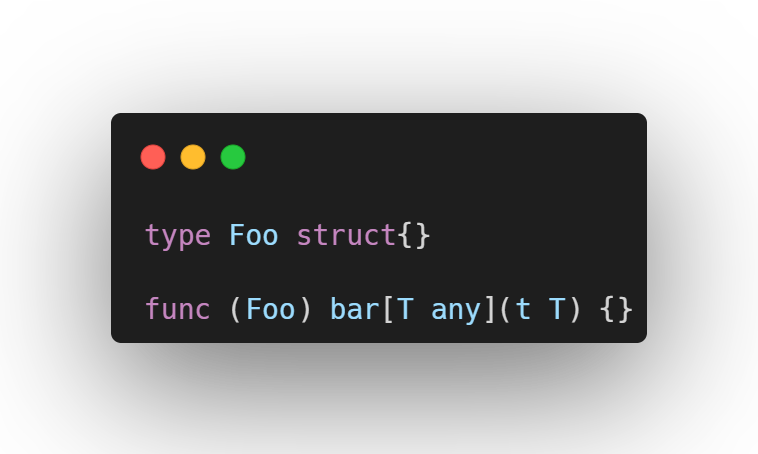
Por fim, é importante destacar que os generics não podem ser utilizados diretamente em métodos de structs, como mostrado a seguir. Caso isso ocorra, o compilador emitirá o erro method must have no type parameters.
Embora os generics possam ser extremamente úteis em situações específicas, é essencial usá-los com cautela. Em muitos casos, a decisão de não utilizá-los se assemelha à decisão de não usar interfaces, pois ambas introduzem um nível de abstração que, se for desnecessário, pode tornar o código mais difícil de entender e manter.
Generics são uma ferramenta poderosa, mas, como toda abstração, envolvem um custo. Se forem utilizados de forma prematura ou sem uma justificativa clara, podem adicionar complexidade sem trazer benefícios reais. Em vez de recorrer a parâmetros de tipo logo no início, devemos primeiro focar em resolver os problemas concretos de forma simples e direta.
Como regra: só considere o uso de generics quando perceber repetição de código entre diferentes tipos. Até lá, mantenha seu código simples, claro e voltado às necessidades reais do projeto.
Referência: HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
Um serviço é um componente de software autônomo que implementa uma funcionalidade específica e pode ter seu deploy de forma independente.
Cada serviço expõe uma API, permitindo que suas funcionalidades sejam acessadas externamente.
Hora do conceito:
API significa Application Programming Interface (Interface de Programação de Aplicações). Trata-se de um conjunto de regras e definições que permite a comunicação entre diferentes sistemas ou aplicações, facilitando a troca de dados e funcionalidades de forma padronizada e segura.
Uma API é composta por comandos, consultas e eventos: • Um comando, como createOrder(), executa ações e modifica dados; • Uma consulta, como findOrderById(), serve para recuperar informações sem causar alterações no sistema; • Um serviço também pode publicar eventos, como OrderCreated, que são consumidos por outros serviços ou aplicações interessadas.
A API de um serviço encapsula sua implementação interna, diferentemente de um monolito, onde um desenvolvedor pode contornar a lógica da aplicação acessando diretamente o código ou o banco de dados. Nos microsserviços, essa possibilidade é eliminada, reforçando a separação de responsabilidades e a proteção da lógica interna.
Como resultado, uma arquitetura baseada em microsserviços promove a modularidade, com cada serviço adotando sua própria arquitetura e tecnologia. Isso permite que mudanças sejam feitas em um serviço sem impactar os demais, favorecendo o baixo acoplamento.
Esse baixo acoplamento proíbe que os serviços compartilhem um banco de dados comum. Os dados persistentes de um serviço devem ser tratados como atributos privados de uma classe, ou seja, acessíveis apenas por ele. Isso permite que os desenvolvedores alterem o schema do banco de forma isolada, sem a necessidade de coordenação com outros times. Além disso, evita bloqueios em tempo de execução, já que um serviço não interfere diretamente no banco de outro.
Os times responsáveis pelos serviços devem ser pequenos, ágeis e autônomos, com ciclos de entrega curtos e mínima dependência de outros times. Se um serviço demanda muitos desenvolvedores, leva muito tempo para ser testado ou implantado, ou ainda exige modificações em outros serviços a cada alteração, é um sinal de que ele precisa ser dividido e melhor desacoplado.
A arquitetura de microsserviços estrutura a aplicação como um conjunto de serviços pequenos, independentes e bem desacoplados.
Como resultado, essa abordagem acelera o desenvolvimento, facilita a manutenção, melhora a escalabilidade, simplifica testes e deploys, e permite que a organização entregue valor de forma mais rápida e eficiente.
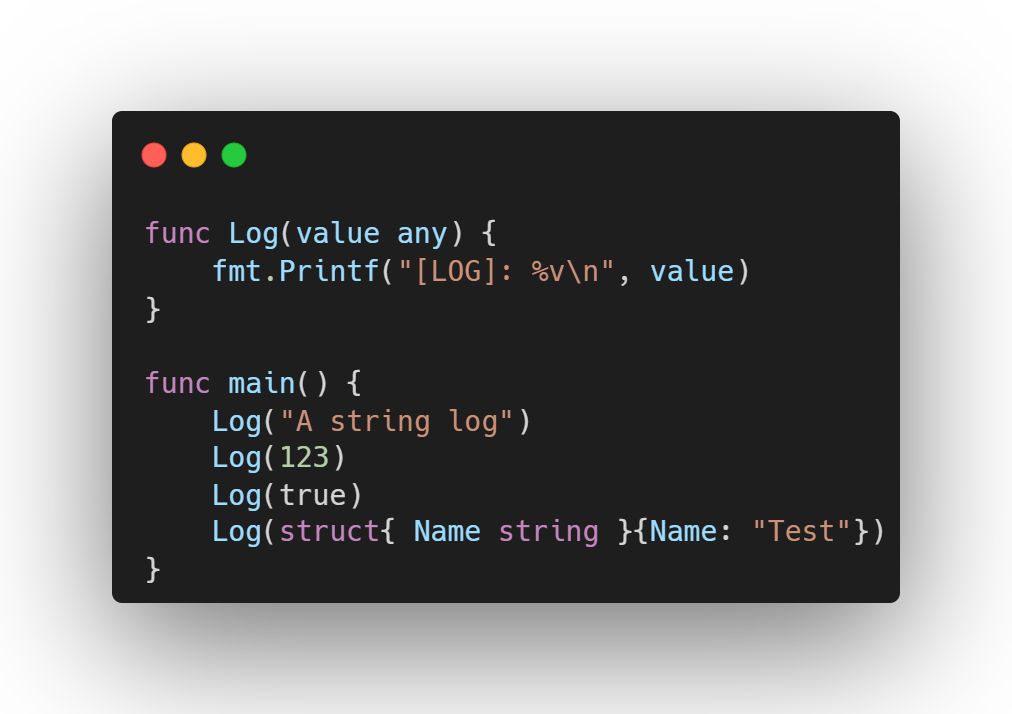
Em Go, interface{} representa uma interface vazia. Isso significa que ela não define nenhum método e, por isso, qualquer tipo de dado em Go a implementa automaticamente. Em outras palavras, ela pode armazenar qualquer tipo e valor.
Esse recurso é útil quando não se sabe, antecipadamente, qual tipo será utilizado como em situações que envolvem deserialização de JSON ou comunicação genérica entre componentes.
No Go 1.18, foi introduzido o tipo any, que nada mais é do que um alias para interface{}.
Observação: A partir deste ponto do texto, usarei apenas any, então lembre-se: any e interface{} são equivalentes.
Na maioria dos casos, o uso do any é considerado uma generalização excessiva (overgeneralization).
Ao utilizá-lo, perde-se a verificação de tipos em tempo de compilação. Isso significa que, para acessar o valor armazenado em um any, geralmente é necessário realizar uma type assertion. Ou seja, é preciso checar se o valor dentro do any é realmente do tipo esperado, o que pode tornar o código mais complexo e propenso a erros.
A type assertion, que consiste em extrair o valor de dentro de um any e convertê-lo de volta para seu tipo original, pode também gerar sobrecarga de desempenho, especialmente se for usada com frequência no código.
O any também pode prejudicar a legibilidade e a manutenibilidade do código, já que não se sabe, com clareza, qual tipo de dado está sendo manipulado.
No exemplo abaixo, não há nenhum erro em nível de compilação no código; no entanto, futuros desenvolvedores que precisarem utilizar a struct Store terão que ler a documentação ou se aprofundar no código para entender como utilizar seus métodos.
Retornar valores do tipo any também pode ser prejudicial, pois não há nenhuma garantia, em tempo de compilação, de que o valor retornado pelo método será utilizado de forma correta e segura, o que pode, inclusive, levar a um panic durante a execução.
Ao utilizar any, perdemos os benefícios do Go ser uma linguagem estaticamente tipada, como a verificação de tipo em tempo de compilação, a detecção precoce de erros e a otimização de desempenho, já que o compilador não precisa realizar verificações de tipo em tempo de execução.
Em vez de utilizar any nas assinaturas dos métodos, recomenda-se criar métodos específicos, mesmo que isso resulte em alguma duplicação, como múltiplas versões de métodos Get e Set.
Ter mais métodos não é necessariamente um problema, pois os clientes que os utilizarão podem criar suas próprias abstrações por meio de interfaces.
Mas o uso de any é sempre ruim? A resposta é: não.
Na programação, raramente existe uma regra sem exceções.
Como mencionado no início do texto, há situações em que o uso de any é justificado, especialmente quando não é possível conhecer antecipadamente o tipo dos dados com os quais se estará lidando, como em:
Serialização e deserialização de JSON quando não se conhece o formato exato do JSON em tempo de compilação.
Cache genérico para armazenar qualquer tipo de valor.
Logger genérico que aceita qualquer tipo de valor.
Embora o uso de any ofereça flexibilidade, ele deve ser evitado sempre que for possível utilizar tipos específicos. Fora de casos bem específicos, prefira manter a tipagem forte do Go para garantir segurança, legibilidade e manutenibilidade do código.
Referência: HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
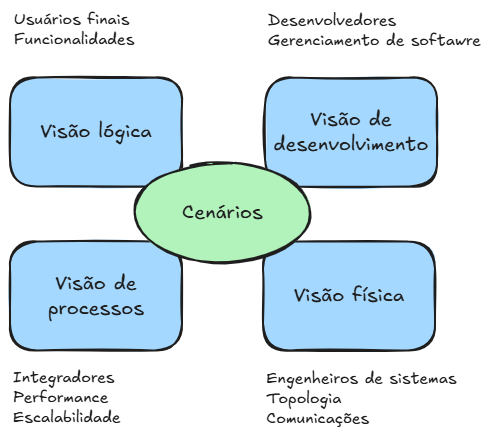
A arquitetura de software pode ser vista sob diferentes perspectivas assim como acontece com a arquitetura de um prédio, que pode ser analisada sob os pontos de vista estrutural, hidráulico, elétrico, entre outros.
Com base nessa ideia, Philippe Kruchten propôs o modelo 4+1 de visões, descrito em um artigo que se tornou referência na área, referenciado a seguir:
Segundo o autor, dividir a arquitetura em múltiplas visões ajuda a tratar separadamente as preocupações dos diferentes stakeholders do sistema como usuários finais, desenvolvedores, engenheiros de software, gerentes de projeto, entre outros.
De forma geral, a arquitetura de software lida com o projeto e a estruturação do sistema em um nível mais alto. Ela fornece uma visão ampla do sistema, sem entrar nos detalhes do código-fonte ou da implementação específica de cada parte.
Essa arquitetura resulta da combinação de elementos estruturais organizados de maneira a atender tanto aos requisitos funcionais quanto aos não funcionais como confiabilidade, escalabilidade, portabilidade e disponibilidade.
Pausa para conceito:
Requisitos funcionais são as funcionalidades que o sistema deve oferecer, ou seja, o que ele deve fazer. Exemplos: autenticar usuários, processar pagamentos, gerar relatórios.
Requisitos não funcionais são as características de qualidade ou restrições do sistema, ou seja, como ele deve se comportar. Exemplos: desempenho, segurança, escalabilidade, usabilidade, confiabilidade.
Para descrever a arquitetura de software, foi desenvolvido um modelo baseado em cinco visões principais:
Visão lógica: representa o modelo de objetos do sistema, especialmente quando se utiliza uma abordagem de design orientado a objetos. Exemplo: a classe Cliente se relaciona com a classe Pedido, formando a base do modelo de domínio do sistema.
Visão de processos: aborda os aspectos de concorrência e sincronização da aplicação. Exemplo: o sistema conta com um processo dedicado ao tratamento de requisições simultâneas de usuários, garantindo integridade dos dados.
Visão física: descreve como o software é distribuído no hardware, refletindo sua arquitetura física e aspectos de desempenho. Exemplo: o serviço de autenticação é executado em um servidor separado, garantindo maior segurança e escalabilidade.
Visão de desenvolvimento: mostra como o software está organizado no ambiente de desenvolvimento, destacando a estrutura dos módulos e componentes. Exemplo: o projeto está dividido em módulos como frontend, backend e bibliotecas compartilhadas, organizados em um repositório central.
Visão de cenários (casos de uso): integra as demais visões por meio de interações reais com o sistema, baseadas nos requisitos funcionais. Essa visão ajuda a validar a arquitetura e orientar sua evolução. Exemplo: o caso de uso “Realizar Compra” percorre simultaneamente elementos das visões lógica, de processos e física.
Para cada visão do modelo 4+1, os arquitetos de software podem escolher um ou mais estilos arquiteturais adequados. Isso permite a coexistência de diferentes estilos em um mesmo sistema, proporcionando flexibilidade e adaptabilidade para atender a múltiplos requisitos, funcionais e não funcionais.
A seguir, aprofundamos cada uma das principais visões arquiteturais:
Arquitetura lógica
A arquitetura lógica foca, principalmente, nos requisitos funcionais do sistema. Ela define como o sistema será decomposto em um conjunto de abstrações, geralmente baseadas no domínio do problema, utilizando princípios da orientação a objetos como abstração, encapsulamento e herança.
Essa decomposição tem como objetivo facilitar a análise funcional e a identificação de mecanismos e elementos de design reutilizáveis, comuns entre diferentes partes do sistema.
Arquitetura de processos
A arquitetura de processos se concentra nos requisitos não funcionais do sistema, abordando aspectos como concorrência, sistemas distribuídos, integridade, tolerância a falhas e a interação entre as abstrações da visão lógica e o processo, como, por exemplo, “em qual thread uma operação sobre um objeto será executada”. Ela lida com o controle e a organização de tarefas e processos que compõem a aplicação, assegurando que o sistema funcione de maneira eficiente e robusta.
Essa arquitetura pode ser descrita por diferentes camadas de abstração, onde cada camada tem sua responsabilidade específica. No nível mais alto, a arquitetura de processos pode ser vista como uma rede de processos lógicos que se comunicam entre si. Várias camadas lógicas podem coexistir simultaneamente, compartilhando recursos físicos como CPU e memória, sem que uma sobrecarregue a outra.
Um processo é o agrupamento de tarefas que formam uma unidade executável e, nesse nível, pode ser controlado, ou seja, pode ser iniciado, interrompido, reconfigurado ou finalizado. Uma característica importante da arquitetura de processos é que os processos podem ser replicados para distribuir a carga de processamento, o que melhora a disponibilidade do sistema, tornando-o mais escalável.
Os programas são frequentemente divididos em tarefas independentes e cada tarefa é representada por uma thread de controle separado. Cada thread pode ser agendada e executada de forma independente em diferentes nós de processamento, o que permite maior flexibilidade e performance no sistema distribuído.
As tarefas principais se comunicam entre si por meio de mecanismos de comunicação bem definidos, como mensagens síncronas e assíncronas, chamadas de procedimento remoto (RPC) e transmissão de eventos. Já as tarefas secundárias podem se comunicar por mecanismos como rendezvous (mecanismo de sincronização em que dois ou mais processos ou threads aguardam uns aos outros para se encontrarem e trocarem dados antes de continuar a execução) ou memória compartilhada.
É importante que as tarefas principais não façam suposições sobre a localização física das tarefas no sistema, ou seja, não devem assumir que estão no mesmo processo ou nó de processamento. Isso garante maior flexibilidade e independência em relação à alocação física do sistema, permitindo uma melhor escalabilidade e portabilidade.
Arquitetura de desenvolvimento
A arquitetura de desenvolvimento foca na organização do software dentro do ambiente de desenvolvimento, onde o sistema é dividido em subsistemas e bibliotecas, que podem ser trabalhados por um ou mais desenvolvedores. Esses subsistemas são organizados de forma hierárquica em camadas, com interfaces bem definidas para comunicação entre elas.
A descrição completa da arquitetura de desenvolvimento só é possível após a identificação de todos os elementos do software, mas regras essenciais, como particionamento, agrupamento e visibilidade, já podem ser estabelecidas.
Essa arquitetura leva em consideração principalmente requisitos internos relacionados à facilidade de desenvolvimento, gerenciamento, reutilização e restrições das ferramentas ou da linguagem usada.
A visão de desenvolvimento serve como base para a alocação de requisitos e tarefas, organização das equipes, planejamento de custos e monitoramento do progresso do projeto. Além disso, é fundamental para a reutilização, portabilidade e segurança do software, sendo crucial para o estabelecimento de uma linha de produto.
Arquitetura física
A arquitetura física foca nos requisitos não funcionais do sistema, como disponibilidade, confiabilidade (tolerância a falhas), desempenho (taxa de transferência) e escalabilidade.
O software é executado em uma rede de computadores ou nós de processamento e os diversos elementos do sistema como redes, processos, tarefas e objetos precisam ser mapeados adequadamente entre esses nós.
O sistema deve suportar várias configurações físicas que podem ser usadas para desenvolvimento, testes ou implantação em diferentes locais ou para diferentes clientes. Por isso, o mapeamento do software para os nós precisa ser altamente flexível, causando o menor impacto possível no código-fonte, para garantir que a arquitetura se adapte facilmente a diferentes cenários e condições operacionais.
Cenários (casos de uso)
Agora é hora de integrar todos os elementos das quatro arquiteturas. As arquiteturas funcionam em conjunto por meio de um conjunto de cenários, que são basicamente casos de uso mais gerais.
Esses cenários servem como uma abstração dos requisitos mais importantes do sistema. Eles desempenham dois papéis principais:
como um impulsionador para a descoberta dos elementos arquitetônicos durante o projeto, ajudando na identificação e definição dos componentes essenciais;
como uma ferramenta de validação e ilustração após a conclusão do projeto arquitetônico, sendo usados para verificar a conformidade da arquitetura e servir como base para os testes do protótipo arquitetônico.
Exemplo de Cenário: Sistema de Compra Online
O usuário acessa o site de compras e faz login: O sistema valida as credenciais inseridas e ativa o perfil de usuário correspondente.
O sistema exibe os produtos disponíveis: O servidor consulta a base de dados e apresenta os produtos organizados por categoria, disponibilidade e preço.
O usuário seleciona um produto e adiciona ao carrinho de compras: O sistema atualiza o carrinho de compras, alocando os recursos necessários para armazenar o item selecionado.
O usuário procede para o checkout e insere os dados de pagamento: O sistema valida os dados inseridos, como número do cartão e endereço de cobrança, e verifica a disponibilidade do pagamento.
Após validação, o sistema confirma a compra e emite um recibo: O sistema processa o pagamento, atualiza o estoque e envia um recibo eletrônico para o usuário, finalizando a transação.
Conclusão
Este modelo de visão “4+1” permite que diferentes partes interessadas acessem as informações que são mais relevantes para elas sobre a arquitetura de software. Engenheiros de sistemas analisam a arquitetura a partir das visões física e de processo. Usuários finais, clientes e especialistas em dados a visualizam pela visão lógica. Já gerentes de projeto e a equipe responsável pela configuração de software a observam a partir da visão de desenvolvimento.
Interfaces oferecem uma forma de especificar o comportamento de um objeto, mesmo que ele ainda não exista.
Elas podem ser utilizadas quando há necessidade de replicar comportamentos, promover o desacoplamento entre componentes ou restringir certas funcionalidades.
Mas surge a pergunta: onde devemos criá-las?
A resposta, na maioria dos casos, é: do lado de quem vai utilizá-las (lado do consumidor).
É comum vermos interfaces sendo definidas junto com suas implementações concretas (lado do produtor), mas essa prática não é a mais recomendada em Go. Isso porque ela pode forçar o consumidor a depender de métodos que não precisa, dificultando a flexibilidade e o reuso.
É o consumidor quem deve decidir se precisa de uma abstração e qual deve ser sua forma.
Essa abordagem segue o Princípio de Segregação de Interface (Interface Segregation Principle, a letra “I” do SOLID), que estabelece que um cliente não deve ser forçado a depender de métodos que não utiliza.
Portanto, a melhor prática é: o produtor fornece implementações concretas e o consumidor decide como usá-las, inclusive se deseja abstraí-las por meio de interfaces.
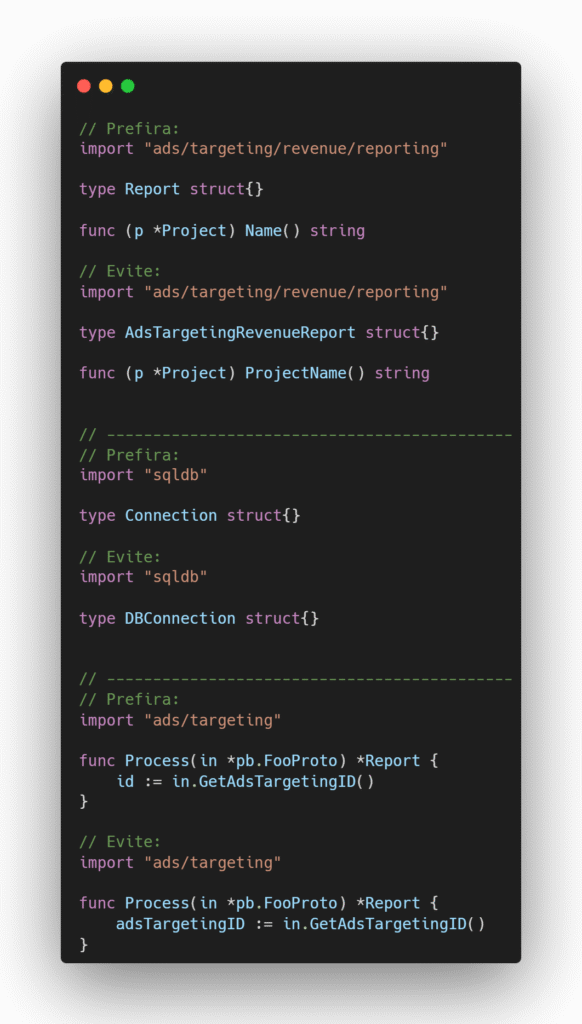
Exemplo
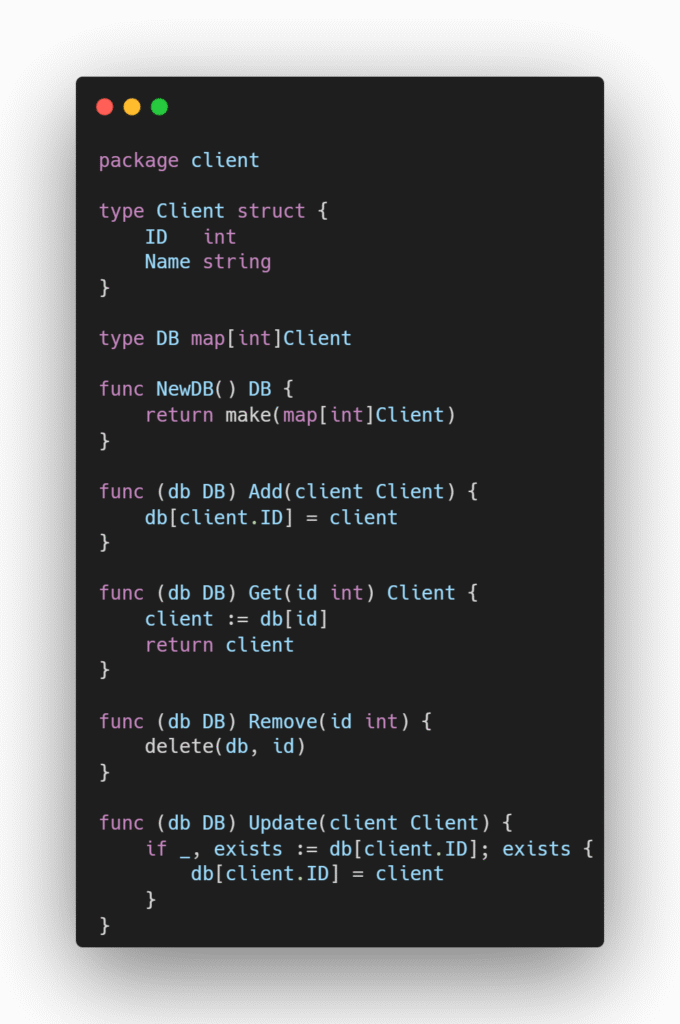
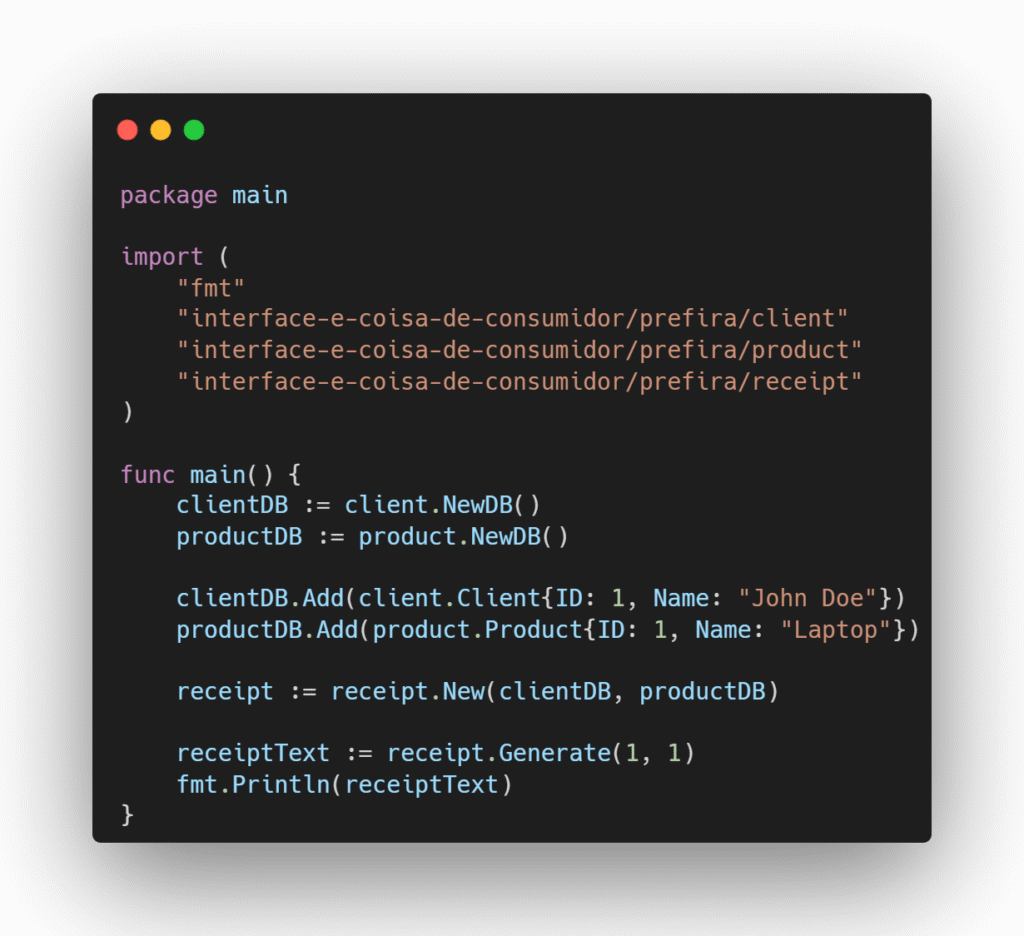
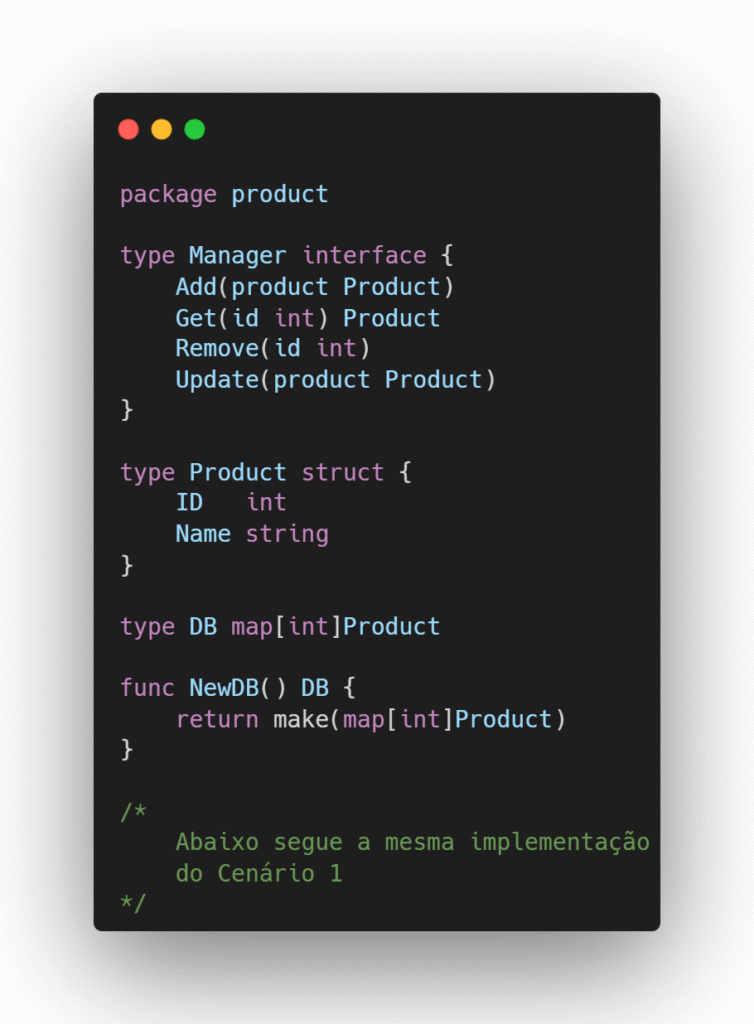
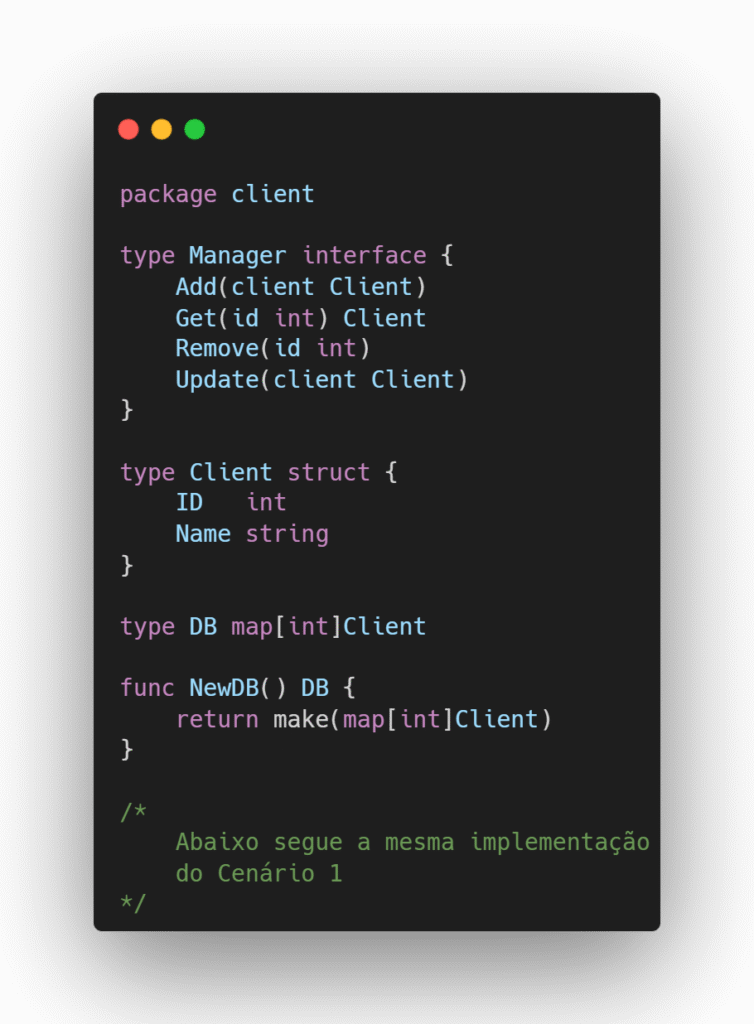
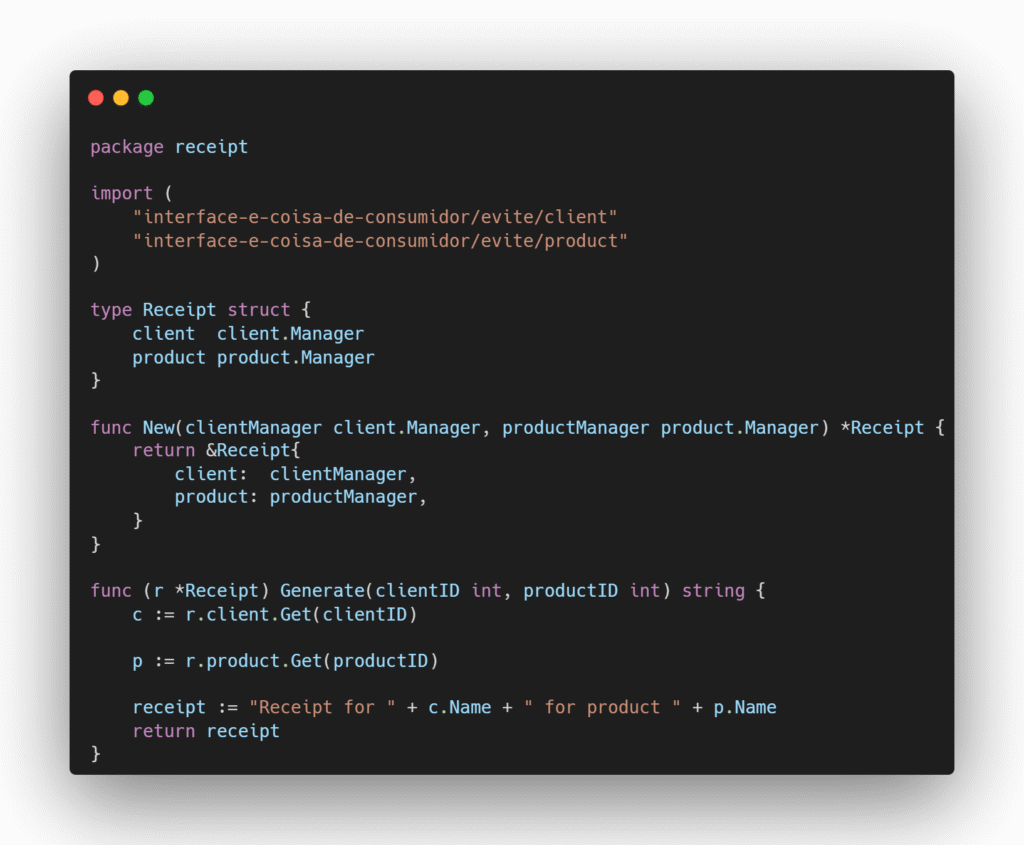
Imagine um sistema em que precisamos gerar um recibo de pedido e para isso precisamos buscar os nomes do cliente e do produto com base em seus respectivos IDs.
Cenário 1 – Prefira: Os produtores fornecem a implementação concreta para acesso a esses dados e o consumidor define as interfaces com os métodos que ele utilizará para gerar o recibo.
Cenário 2 – Evite: As interfaces são criadas no lado dos produtores e o pacote receipt acaba tendo acesso a métodos que não precisa, o que gera acoplamento desnecessário e fere o princípio de segregação de interface.
Em alguns contextos específicos, pode fazer sentido definir a interface no lado do produtor. Nesses casos, o ideal é mantê-la o mais enxuta possível, para favorecer a reutilização e facilitar sua composição com outras interfaces.
Por exemplo: um pacote que fornece um cliente HTTP para consumo de uma API externa, como um serviço de pagamentos. Esse pacote pode expor uma interface com métodos como CreateCharge, RefundPayment e GetTransactionStatus, permitindo que qualquer sistema que consuma o pacote saiba exatamente quais operações são suportadas.
Como o próprio pacote é o especialista no domínio da API externa, ele pode definir uma interface enxuta e bem estruturada, facilitando tanto o uso quanto a substituição por implementações mockadas.
Leitura complementar
As abstrações devem ser descobertas e não criadas. Isso significa que não se deve criar abstrações se não há uma real necessidade no momento. Criam-se interfaces quando necessário e não quando se prevê que elas serão utilizadas.
Quando se criam muitas interfaces, o fluxo do código fica mais complexo, dificultando a leitura e o entendimento do sistema.
Se não existe uma razão para definir uma interface, e é incerto que ela melhorará o código, devemos questionar o motivo da existência dela e por que não simplesmente chamar a implementação concreta.
É comum que desenvolvedores exagerem (overengineer), tentando adivinhar qual seria o nível perfeito de abstração com base no que acreditam que será necessário no futuro. Porém, isso deve ser evitado, pois, na maioria dos casos, polui o código com abstrações desnecessárias.
Referência: HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
Uma das perguntas mais frequentes sobre Go é se existe algum guia de estilo para a escrita de código, como a nomenclatura de variáveis, funções e pacotes, semelhante ao PEP 8 do Python.
Essa dúvida, inclusive, está presente na página de Frequently Asked Questions (FAQ) da documentação oficial da linguagem, na seguinte pergunta:
Is there a Go programming style guide?
E a resposta é:
There is no explicit style guide, although there is certainly a recognizable “Go style”. (Não existe um guia de estilo explícito, embora haja certamente um “estilo Go” reconhecível.)
O que existe são convenções para orientar sobre nomenclatura, layout e organização de arquivos.
O gofmt, ferramenta oficial da linguagem de programação Go, formata automaticamente o código-fonte de acordo com o estilo padrão da linguagem. Embora não seja obrigatório, esse estilo é amplamente adotado pela comunidade como o jeito certo de escrever código Go. O gofmt pode ser integrado a IDEs como o Visual Studio Code, permitindo que a formatação seja aplicada automaticamente sempre que o arquivo for salvo.
Existem também documentos que contêm conselhos sobre esses tópicos, como:
O guia mais completo que encontrei até hoje é o Go Style Decisions, publicado pelo Google (vale lembrar que a linguagem Go surgiu dentro da própria empresa). Esse guia é, inclusive, referenciado na documentação oficial do Go, na página Go Code Review Comments.
Considero esse documento minha principal referência quando o assunto é estilo, e abaixo destaco os pontos mais relevantes sobre nomenclatura, segundo a minha visão pessoal:
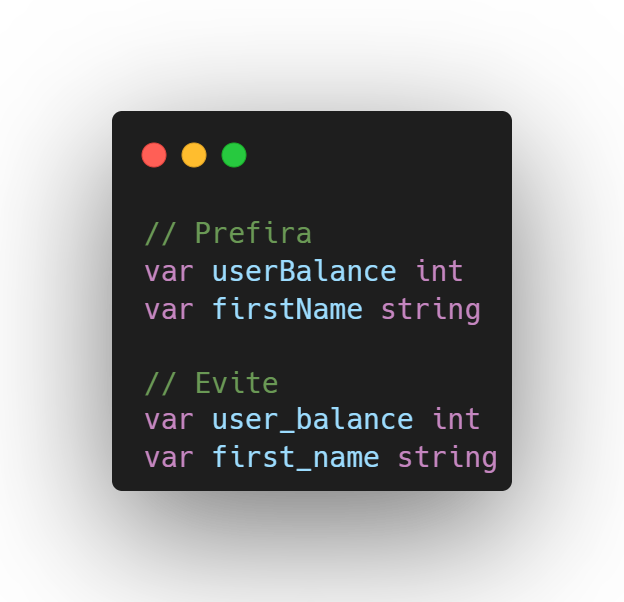
No código Go, utiliza-se CamelCase em vez de underscores, como no snake_case, para nomes compostos por várias palavras dos identificadores.
Nota: Os nomes dos arquivos de código-fonte não são identificadores Go e, portanto, não precisam seguir as mesmas convenções de nomenclatura. Eles podem conter underscores, como, por exemplo, my_api_handlers.go (isso é até o recomendado para esses casos).
Pacotes
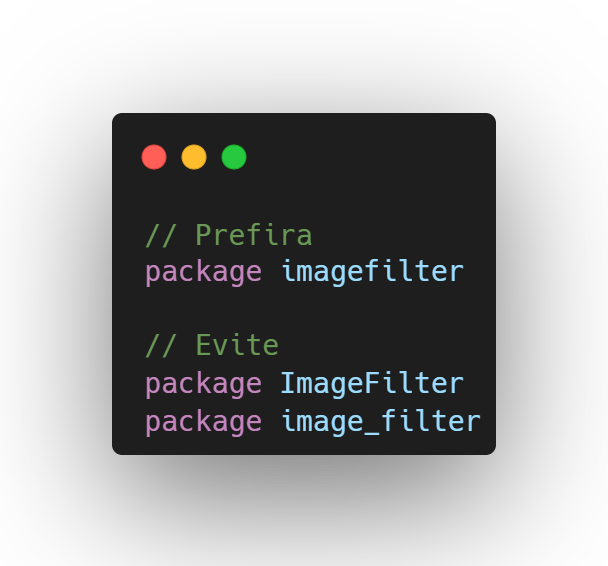
Os nomes dos pacotes devem ser curtos e conter somente letras minúsculas.
Se forem compostos por múltiplas palavras, elas devem ser escritas juntas, sem separação ou caracteres especiais.
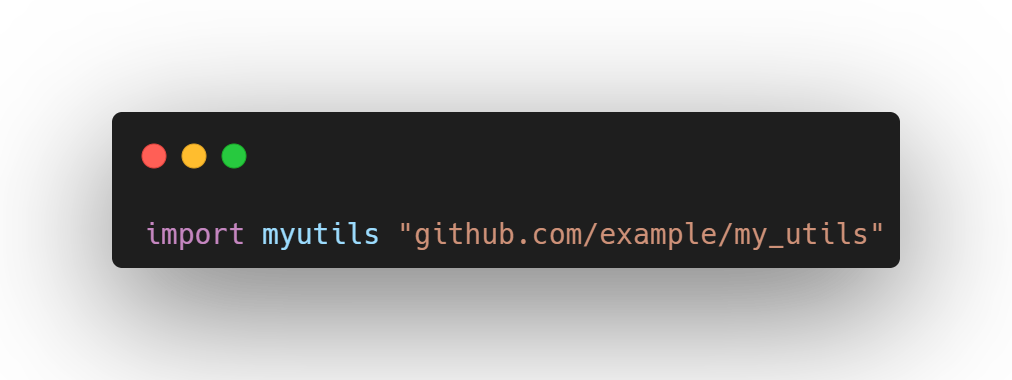
Se for necessário importar um pacote cujo nome contenha underscore (geralmente código de terceiros), ele deve ser renomeado durante a importação para um nome mais adequado seguindo as boas práticas.
Seja consistente usando sempre o mesmo nome para o mesmo pacote importado em diferentes arquivos.
Evite usar nomes que também possam ser utilizados por variáveis, a fim de prevenir sombreamento no código.
Exceção a regra:
Quando for necessário testar um pacote como um usuário externo, ou seja, testando apenas sua interface pública, é preciso adicionar o sufixo *_test ao nome do pacote nos arquivos de teste.
Isso força a importação explícita do pacote, permitindo a realização do chamado teste de caixa-preta (black box testing).
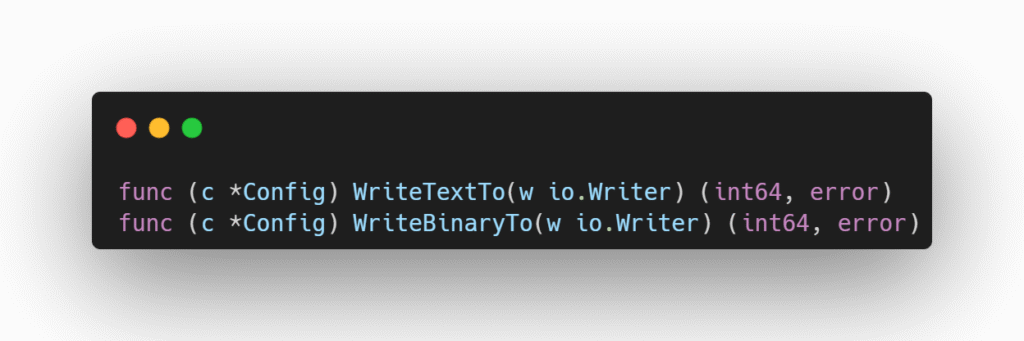
Eles devem ser curtos, sendo uma ou duas letras do próprio nome, e usados de forma igual para todos os métodos daquele tipo.
Prefira
Evite
func (t Tray)
func (tray Tray)
func (ri *ResearchInfo)
func (info *ResearchInfo)
func (w *ReportWriter)
func (this *ReportWriter)
func (s *Scanner)
func (self *Scanner)
Constantes
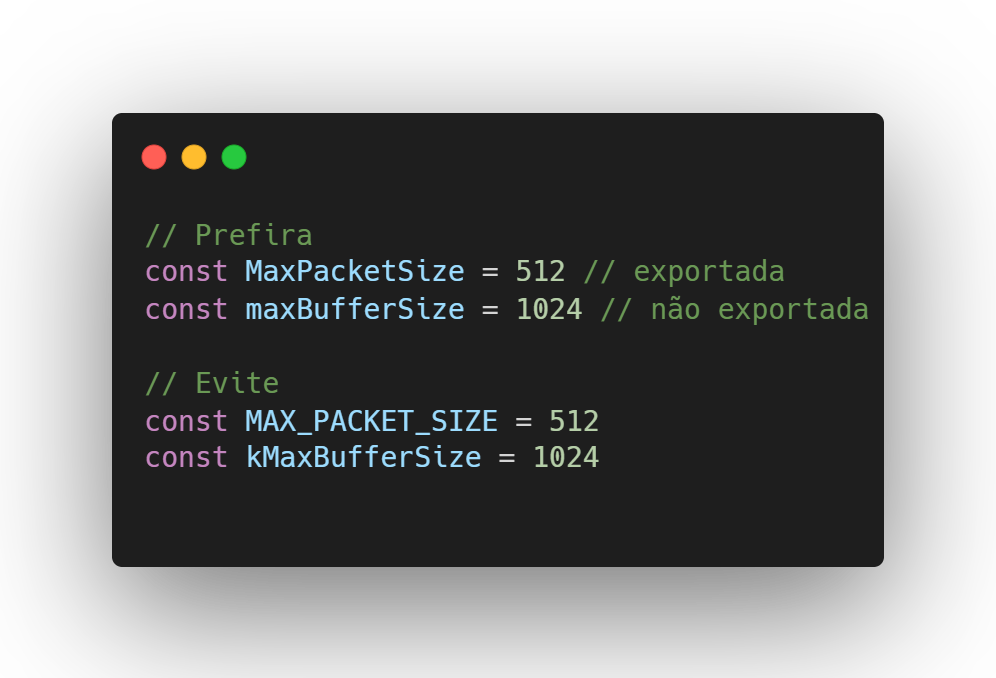
Deve ser utilizado CamelCase, assim como os outros nomes.
Constantes exportadas começam com letra maiúscula, enquanto constantes não exportadas começam com letra minúscula.
Isso se aplica mesmo que contrarie convenções de outras linguagens, como em Java, onde as constantes são geralmente todas maiúsculas e com underscore. Por exemplo, MAX_RETRIES se tornaria MaxRetries em Go.
Além disso, não é necessário começar o nome com a letra “k”.
Siglas
Palavras em nomes que são siglas ou acrônimos (ex: URL e OTAN) devem manter a capitalização (todo maiúsculo ou tudo minúsculo).
Em nomes com múltiplas siglas (ex: XMLAPI, pois contém XML e API), cada letra de uma mesma sigla deve ter a mesma capitalização, mas as siglas diferentes podem usar capitalizações distintas.
Se a sigla contiver letras minúsculas (ex: DDoS, iOS, gRPC), ela deve manter a forma original, a menos que precise mudar a primeira letra para exportação (como em linguagens de programação).
Nome
Escopo
Prefira
Evite
XML API
Exportada
XMLAPI
XmlApi, XMLApi, XmlAPI, XMLapi
XML API
Não exportada
xmlAPI
xmlapi, xmlApi
iOS
Exportada
IOS
Ios, IoS
iOS
Não exportada
iOS
ios
gRPC
Exportada
GRPC
Grpc
gRPC
Não exportada
gRPC
grpc
DDoS
Exportada
DDoS
DDOS, Ddos
DDoS
Não exportada
ddos
dDos, dDOS
ID
Exportada
ID
ID
ID
Não exportada
id
iD
DB
Exportada
DB
Db
DB
Não exportada
db
dB
Getters
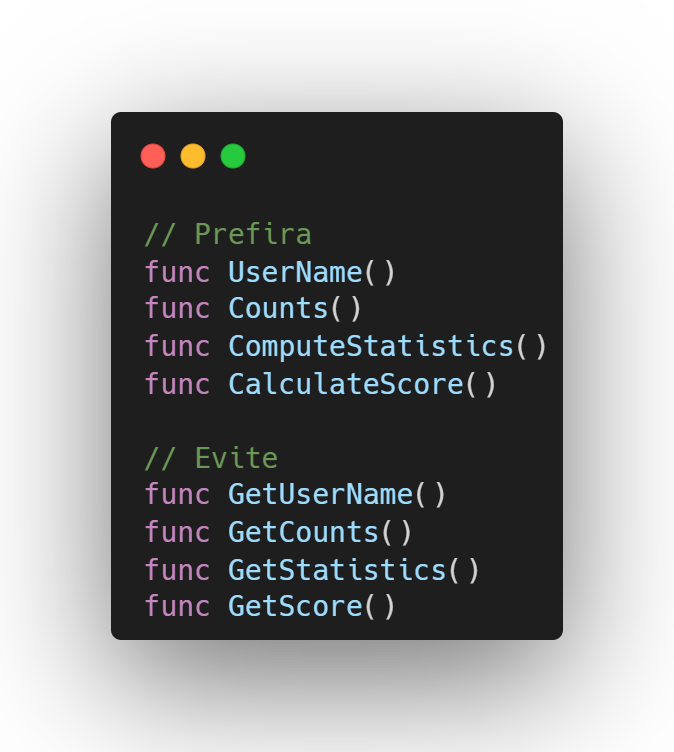
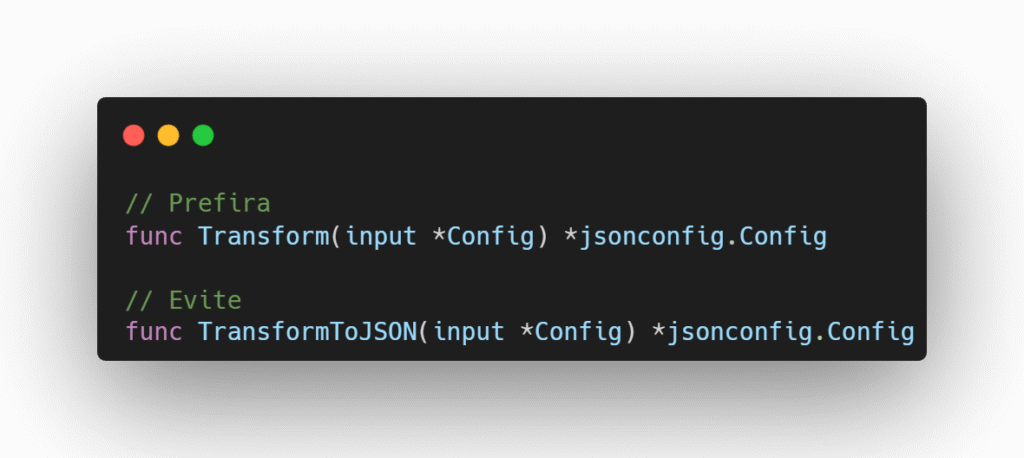
Nomes de funções e métodos não devem utilizar o prefixo “Get” ou “get”, a menos que o conceito envolva a palavra “get” de forma natural (como em uma requisição HTTP GET).
Prefira começar o nome diretamente com o substantivo. Por exemplo, use Counts em vez de GetCounts.
Se a função envolve um cálculo complexo ou a execução de uma chamada remota, é recomendável usar palavras como Compute (calcular) ou Fetch (buscar), em vez de Get, para deixar claro ao desenvolvedor que a execução da função pode demorar, bloquear ou falhar.
Repetição
Um código deve evitar repetições desnecessárias, que podem ocorrer de diferentes formas, especialmente na nomeação de pacotes, variáveis, constantes ou funções exportadas.
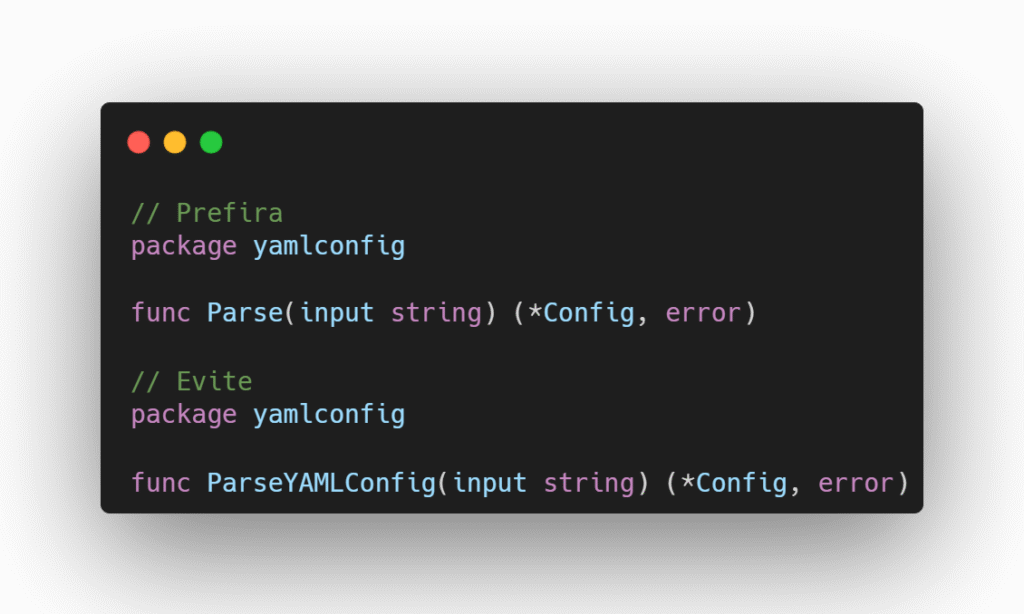
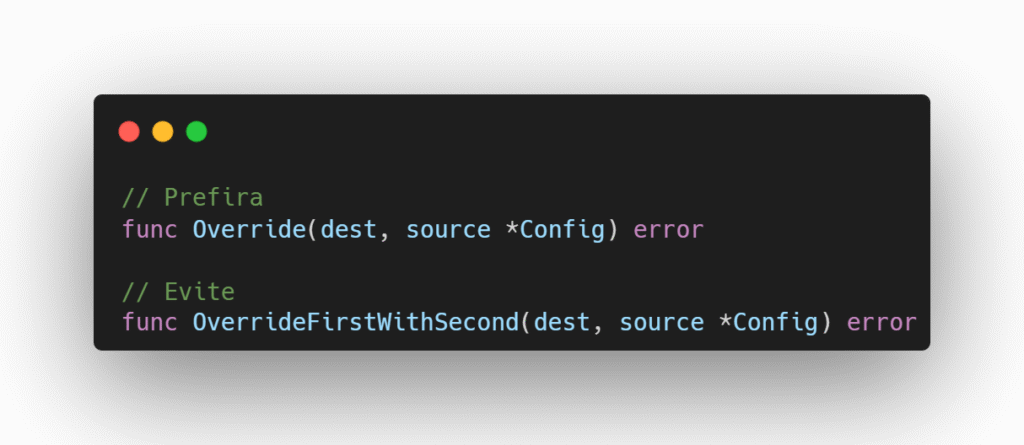
Nas funções, não repita o nome do pacote:
Mais exemplos:
Prefira
Evite
widget.New
widget.NewWidget
widget.NewWithName
widget.NewWidgetWithName
db.Load
db.LoadFromDatabase
gtutil.CountGoatsTeleported goatteleport.Count
goatteleportutil.CountGoatsTeleported
mtpb.MyTeamMethodRequest myteampb.MethodRequest
myteampb.MyTeamMethodRequest
Nos métodos, não repita o nome do receptor:
Não repita o nome das variáveis passadas por parâmetros:
Não repita os nomes e tipos dos valores de retorno:
Quando for necessário remover a ambiguidade de funções de nomes similares, é aceitável incluir informações adicionais.
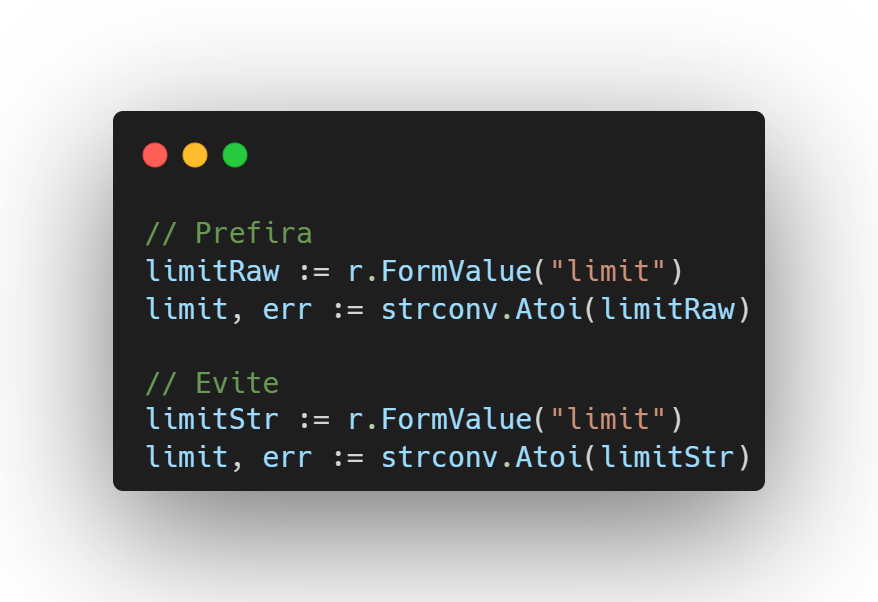
Nome da variáveis VS tipo
O compilador sempre conhece o tipo de uma variável, e na maioria dos casos, o tipo também é claro para o desenvolvedor com base em como a variável é utilizada.
Só é necessário especificar o tipo de uma variável quando seu valor aparecer duas vezes no mesmo escopo.
Se o valor aparece em múltiplas formas, isso pode ser esclarecido com o uso de uma palavra adicional, como raw (bruto) e parsed (processado).
Contexto externo VS nomes locais
Nomes que incluem informações já presentes no contexto ao redor geralmente adicionam ruído desnecessário, sem agregar benefícios.
O nome do pacote, do método, do tipo, da função, do caminho de importação e até mesmo o nome do arquivo já fornecem contexto suficiente para qualificar automaticamente todos os nomes dentro deles.
Leitura complementar
Qual seria um tamanho bom de um nome de variável, constantes e função?
A regra é que o tamanho do nome deve ser proporcional ao escopo dele e inversamente proporcional ao número de vezes que ele é usado dentro desse escopo.
Uma variável com escopo de arquivo pode precisar de várias palavras, enquanto uma variável dentro de um bloco interno (como um IF ou um FOR) pode ser um nome curto ou até uma única letra, para manter o código claro e evitar informações desnecessárias.
Aqui está uma orientação (não é regra) do que seria o tamanho de cada escopo em linhas.
Escopo pequeno: uma ou duas pequenas operações, entre 1 e 7 linhas.
Escopo médio: algumas pequenas operações ou uma grande operação, entre 8 e 15 linhas.
Escopo grande: uma ou algumas operações grandes, entre 15 e 25 linhas.
Escopo muito grande: várias operações que podem envolver diferentes responsabilidades, mais de 25 linhas.
Um nome que é claro em um escopo pequeno (por exemplo, c para um contador) pode não ser suficiente em um escopo maior, exigindo mais clareza para lembrar ao desenvolvedor de seu propósito.
A especificidade do conceito também pode ajudar a manter o nome de uma variável conciso. Por exemplo, se houver apenas um banco de dados em uso, um nome curto como db, que normalmente seria reservado para escopos pequenos, pode continuar claro mesmo em um escopo maior.
Nomes de uma única palavra, como count e options, são um bom ponto de partida. Caso haja ambiguidade, palavras adicionais podem ser incluídas para torná-los mais claros, como userCount e projectCount.
E como dica final: evite remover letras para reduzir o tamanho do nome, como em Sbx em vez de Sandbox, pois isso pode prejudicar a clareza. No entanto, há exceções, como nomes amplamente aceitos pela comunidade de forma reduzida, como db para database e ctx para context.
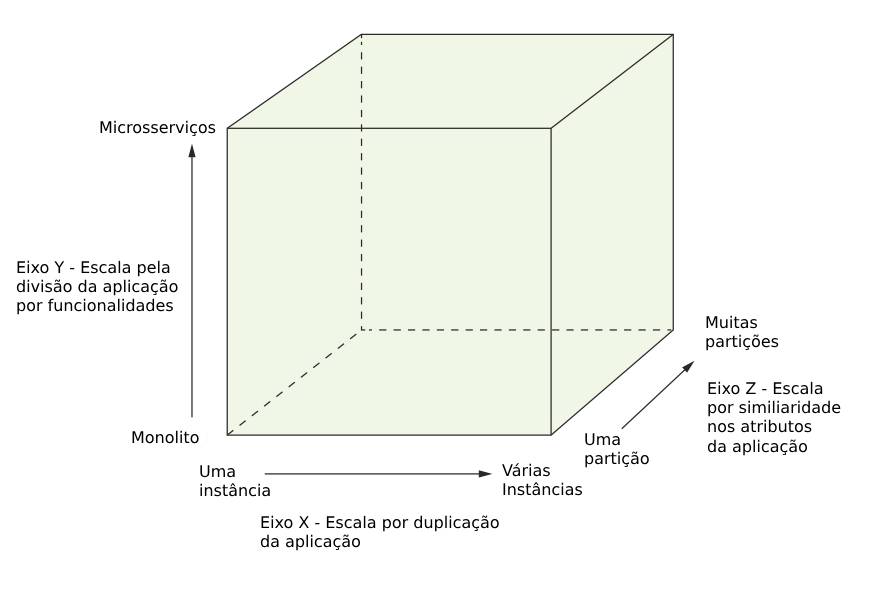
O cubo da escalabilidade AFK é um modelo tridimensional que representa diferentes estratégias de escalabilidade de sistemas. Ele é composto por três eixos (X, Y e Z), cada um correspondendo a uma abordagem distinta para escalar aplicações, bancos de dados e até organizações.
Ele foi criado por Abbott, Fisher e Kimbrel, daí a sigla AFK, e foi introduzido no livro “The Art of Scalability”.
O ponto de origem do cubo, definido por x = 0, y = 0, z = 0, representa um sistema monolito ou uma organização composta por uma única pessoa que realiza todas as tarefas, sem qualquer especialização ou divisão com base na função, no cliente ou no tipo de solicitação. À medida que se move ao longo de qualquer um dos eixos, X, Y ou Z, o sistema se torna mais escalável por meio de diferentes estratégias, como a separação por funcionalidades, segmentação por tipo de cliente ou usuário, e replicação para distribuição de carga.
A imagem a seguir apresenta o cubo específico para aplicações.
Eixo X
Representa uma forma de escalar sistemas clonando a aplicação. Isso significa criar várias cópias idênticas do mesmo sistema e distribuir as requisições entre elas. Essa distribuição é feita por um balanceador de carga (load balancer), que envia os pedidos dos usuários para uma das instâncias disponíveis.
Esse tipo de escalabilidade é muito comum e fácil de entender. Ele funciona bem para lidar com o aumento do número de acessos, melhorando a capacidade (mais usuários ao mesmo tempo) e a disponibilidade (mais chances de continuar funcionando se uma instância falhar). Além disso, é uma solução de baixo custo e simples de aplicar, já que basta copiar o sistema que já existe.
No entanto, o eixo X tem limitações. Como todas as instâncias são iguais, se o sistema for muito grande ou tiver muitos dados, ele pode ficar lento. Isso porque, mesmo com mais cópias, o sistema ainda é um monolito, e esse tipo de estrutura não lida bem com crescimentos muito complexos.
Eixo Y
Trata da divisão da aplicação por funcionalidades. Isso significa separar o sistema em partes menores, chamadas de serviços, onde cada um cuida de uma função específica, como gerenciamento de pedidos ou de clientes.
Essa divisão ajuda a resolver problemas que surgem quando a aplicação cresce e fica mais complexa. Com essa separação, cada serviço pode funcionar de forma independente, o que melhora o desempenho, facilita a manutenção e evita que falhas em uma parte do sistema afetem as outras.
Apesar de ser mais cara que outras formas de escalabilidade, como duplicar servidores (eixo X), a escalabilidade pelo eixo Y é muito eficaz para organizar o código e permitir que ele cresça de forma sustentável.
Essa abordagem é a base da arquitetura de microsserviços, onde a aplicação é formada por vários serviços pequenos e especializados. Cada um desses serviços pode ser escalado separadamente, conforme a necessidade.
Eixo Z
Trata da separação do trabalho com base em atributos dos pedidos, como o cliente ou o usuário que está fazendo a requisição. Ou seja, em vez de cada instância da aplicação cuidar de todos os dados, cada uma cuida apenas de uma parte, como um grupo específico de usuários.
Essa abordagem ajuda a escalar o sistema quando há crescimento no número de clientes, transações ou volume de dados. Cada instância da aplicação fica responsável por uma “fatia” dos dados, o que reduz o tempo de processamento e melhora o desempenho geral.
Embora o software não precise ser dividido em vários serviços como no eixo Y, ele precisa ser escrito de forma que permita essa separação, o que pode aumentar o custo e a complexidade da implementação.
Em resumo, a escalabilidade pelo eixo Z é ideal para lidar com grandes volumes de dados e usuários, dividindo a carga de forma inteligente entre diferentes instâncias da aplicação.
Combinando os três eixos, o cubo da escalabilidade AFK oferece uma visão completa e prática de como evoluir sistemas conforme crescem em uso, dados e complexidade. Cada eixo resolve diferentes tipos de desafios: o X melhora capacidade e disponibilidade com cópias idênticas; o Y reduz a complexidade por meio da divisão funcional; e o Z permite lidar com grandes volumes de dados e usuários por meio da segmentação. Juntos, esses eixos ajudam arquitetos e desenvolvedores a escolher as melhores estratégias de escalabilidade de acordo com as necessidades do sistema, promovendo soluções mais eficientes, resilientes e preparadas para o crescimento.
Referências:
ABBOTT, Martin L.; FISHER, Michael T.. The Art of Scalability: scalable web architecture, processes, and organizations for the modern enterprise. Boston: Addison-Wesley, 2010.