A ordenação de elementos em um array é uma tarefa frequentemente utilizada em diversos programas. Embora existam muitos algoritmos de ordenação bem conhecidos, ninguém quer ficar copiando blocos de código de um projeto para outro.
Por isso, o Go oferece a biblioteca nativa sort.
Ela permite ordenar arrays in-place (a ordenação é feita diretamente na estrutura de dados original, sem criar uma cópia adicional do array) com qualquer critério de ordenação, utilizando uma abordagem baseada em interfaces.
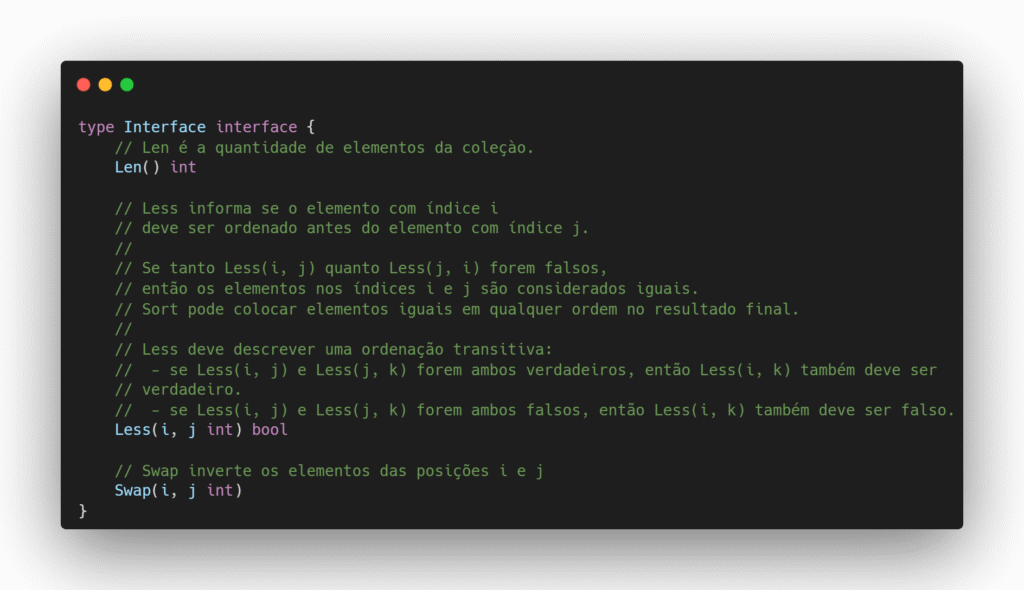
A função sort.Sort não faz suposições sobre a estrutura dos dados; ela apenas exige que o tipo a ser ordenado implemente a interface sort.Interface, que define três métodos essenciais apresentados a seguir.
Um ótimo exemplo inicial é o tipo sort.StringSlice, fornecido pela própria biblioteca sort. Ele já implementa a interface sort.Interface, conforme mostrado abaixo:
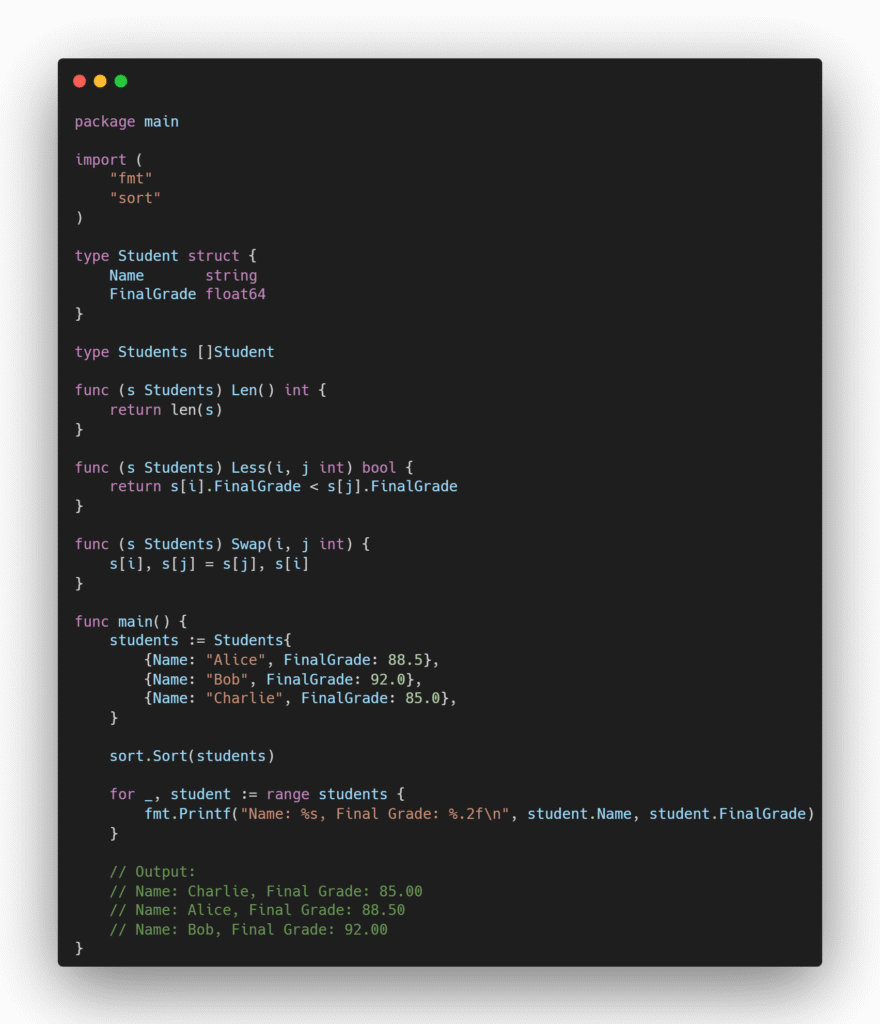
Seguindo essas regras, é possível ordenar structs com base em seus campos como no exemplo a seguir, que ordena uma lista de alunos pela nota:
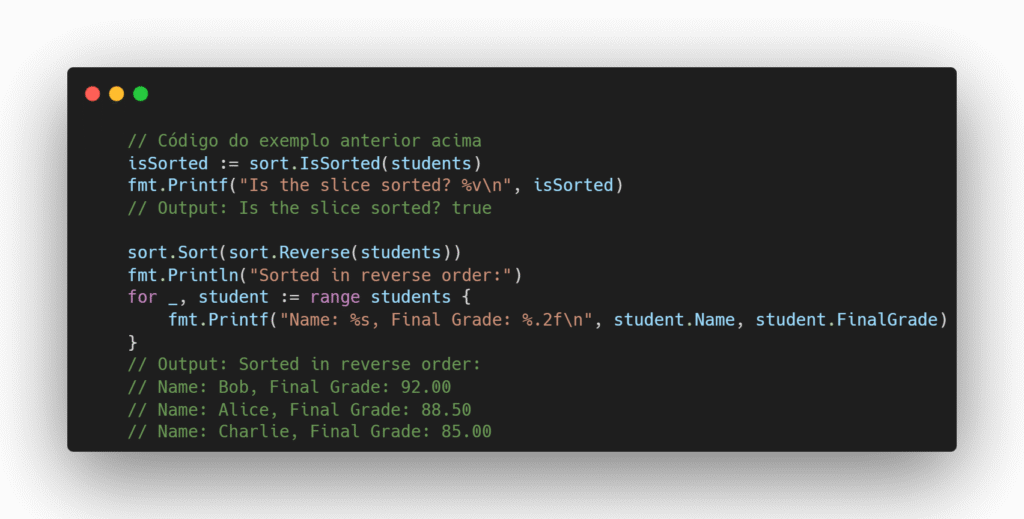
Com a estrutura já definida, também é possível verificar se o array está ordenado usando sort.IsSorted, além de realizar a ordenação em ordem reversa com sort.Reverse. As funções são demonstradas abaixo, utilizando a mesma estrutura do exemplo anterior.
A biblioteca também oferece outras funções bastante úteis:
Ints(x []int): ordena uma slice de inteiros em ordem crescente.
IntsAreSorted(x []int) bool: verifica se o slice x está ordenada em ordem crescente.
Strings(x []string): ordena um slice de strings em ordem crescente.
StringsAreSorted(x []string) bool: verifica se a slice x está ordenada em ordem crescente.
ATENÇÃO
Na própria documentação do pacote sort, na data de escrita deste artigo, existe uma nota na função sort.Sort que diz o seguinte:
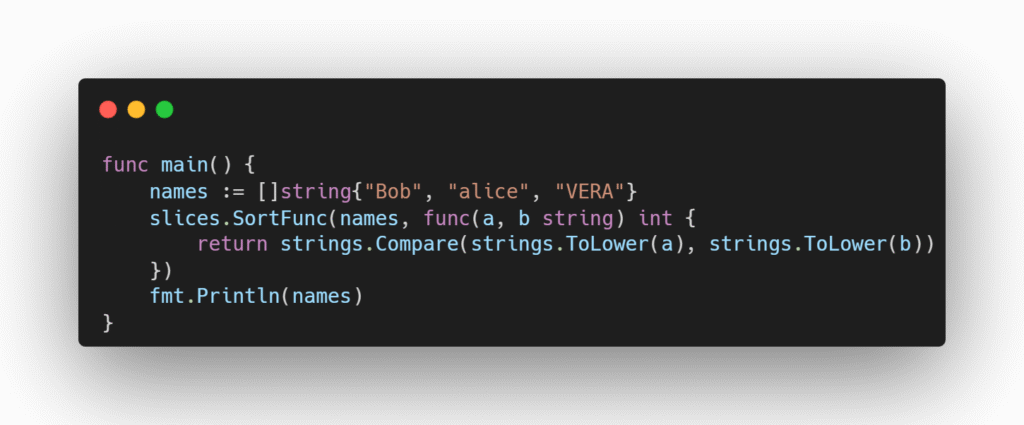
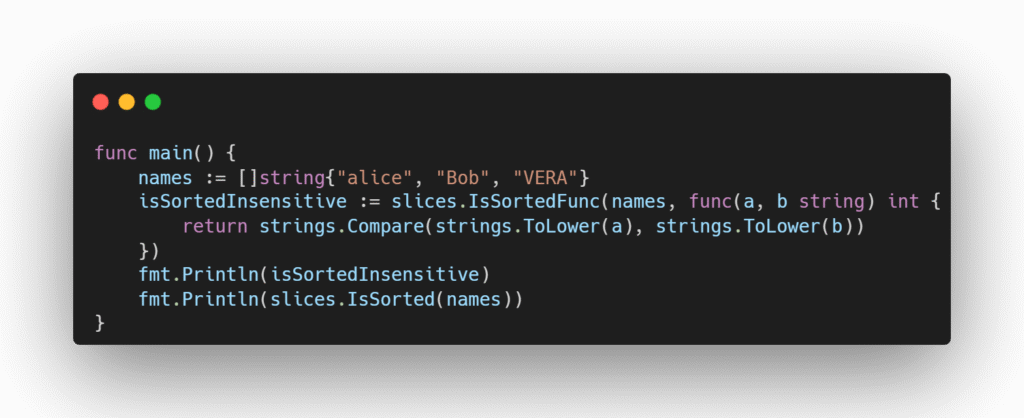
Em muitas situações, a função mais recente slices.SortFunc é mais ergonômica e apresenta melhor desempenho.
Essa mesma nota se encontra na função sort.IsSorted:
Em muitas situações, a função mais recente slices.IsSortedFunc é mais ergonômica e apresenta melhor desempenho.
Em ambos os casos, recomendo avaliar qual abordagem adotar com base no que for mais vantajoso para a sua situação: a simplicidade das funções do pacote sort ou a possível otimização oferecida pelo pacote slices.
Para descobrir qual delas apresenta melhor desempenho no seu contexto, utilize os benchmarks do Go (fica aqui o dever de casa para você, caro leitor, dar uma conferida nisso).
A partir do Go 1.22, algumas funções do pacote sort já utilizam a biblioteca slices internamente, como é o caso de sort.Ints, que usa slices.Sort, e sort.IntsAreSorted, que usa slices.IsSorted.
Para saber mais, confira as documentações oficiais:
Os microsserviços são um padrão de arquitetura de software no qual o sistema é dividido em vários serviços pequenos e independentes que se comunicam entre si. Cada serviço funciona como uma unidade modular isolada, com barreiras bem definidas. Em vez de acessarem diretamente funções ou pacotes uns dos outros, os serviços interagem exclusivamente por meio de APIs. Isso promove um baixo acoplamento entre os componentes do sistema.
Essa abordagem é especialmente útil no desenvolvimento de sistemas grandes e complexos. À medida que o sistema cresce, torna-se cada vez mais difícil mantê-lo como o monolito (conforme discutido em Monolito: um começo inteligente, não um erro), além de ser mais complicado para uma única pessoa compreendê-lo por completo.
Os principais benefícios dos microsserviços são:
Cada serviço é pequeno e fácil de manter (não é à toa o prefixo “Micro”)
Cada serviço deve ser pequeno, o que facilita sua manutenção e evolução ao longo do tempo. Por conta do tamanho reduzido, o código torna-se mais simples de entender, tanto em relação ao que o serviço deve fazer quanto à forma como ele realiza suas tarefas. Esse fator também impacta positivamente o desempenho da aplicação, pois serviços menores tendem a ser desenvolvidos e executados mais rapidamente, o que, por sua vez, contribui para o aumento da produtividade das equipes de desenvolvimento.
Serviços são independentes
Cada serviço pode ser entregue e escalado de forma independente, sem depender diretamente de outros serviços. Isso acelera a entrega de soluções ao mercado e aos clientes, reduz o tempo de resposta para corrigir bugs que afetam o usuário e aumenta a satisfação do cliente ao permitir entregas constantes de valor.
Além disso, cada equipe dentro da empresa pode ser responsável por um ou mais serviços específicos, o que facilita a autonomia dos times. Assim, cada equipe consegue desenvolver, implantar e escalar seus serviços sem depender do andamento dos demais times, promovendo agilidade e especialização.
Ponto de atenção
Quando é necessário implantar soluções que envolvem múltiplos serviços, é fundamental que essa implantação seja cuidadosamente coordenada entre os times. Isso evita que alterações em um serviço causem falhas em outro. É necessário criar um plano de implementação que respeite as dependências entre os serviços, definindo uma ordem lógica de implantação. Essa abordagem contrasta com o monolito, na qual é possível atualizar vários componentes de forma conjunta e atomizada.
Isolamento de falhas
A independência de cada serviço garante o isolamento de falhas dentro do sistema. Por exemplo, se um erro crítico acontece no serviço A, o serviço B pode continuar operando normalmente. Esse isolamento evita que falhas se propaguem, aumentando a resiliência da aplicação como um todo. Em contraste com o monolito em que uma falha em um componente pode derrubar o sistema inteiro.
Permite experimentos e adoção de novas tecnologias
Como os serviços são pequenos e isolados, reescrevê-los utilizando novas linguagens ou tecnologias se torna uma tarefa viável e de baixo risco. Essa flexibilidade permite que equipes experimentem soluções mais modernas e eficientes. Caso a nova abordagem não traga os resultados esperados, o serviço pode ser descartado ou revertido sem comprometer o restante do sistema.
Mas nem tudo são flores…
No mundo da tecnologia, não existe uma bala de prata.
Como qualquer abordagem arquitetural, os microsserviços também apresentam desvantagens que devem ser cuidadosamente consideradas antes da adoção.
Definir cada serviço é custoso
Não existe uma metodologia universal e precisa para decompor um sistema em serviços. Essa tarefa exige conhecimento profundo do domínio do negócio e experiência em design de sistemas. Uma decomposição mal feita pode resultar em um monolito distribuído, que consiste em um conjunto de serviços fortemente acoplados que precisam ser implantados juntos. Esse cenário combina o pior dos dois mundos: a rigidez do monolito com a complexidade dos microsserviços, sem os reais benefícios de nenhum dos dois.
Sistemas distribuídos são complexos
Ao optar por microsserviços, os desenvolvedores precisam lidar com a complexidade natural de sistemas distribuídos. A comunicação entre serviços se dá por mecanismos de comunicação entre processos, como chamadas HTTP ou mensagens assíncronas, que são mais complexas do que simples chamadas de método dentro de uma aplicação monolítica. Além disso, os serviços devem ser preparados para lidar com falhas parciais, como indisponibilidade de outros serviços ou alta latência nas respostas.
Essa complexidade técnica exige que os times tenham habilidades mais avançadas em desenvolvimento, arquitetura e operações. Além disso, há uma carga operacional significativa: múltiplas instâncias de diferentes serviços precisam ser monitoradas, escaladas, atualizadas e gerenciadas em produção. Para que os microsserviços funcionem bem, é necessário investir em um alto grau de automação, incluindo integração contínua, entrega contínua, provisionamento de infraestrutura e observabilidade.
Decidir quando adotar microsserviços é desafiador
Outro desafio importante está relacionado ao momento certo de adotar a arquitetura de microsserviços. Em muitos casos, especialmente no início do desenvolvimento de um novo sistema, os problemas que os microsserviços resolvem ainda não existem. A escolha por uma arquitetura distribuída desde o início pode tornar o desenvolvimento mais lento e oneroso. Isso é particularmente crítico em startups, cujo foco inicial costuma ser validar o modelo de negócio e lançar rapidamente. Para essas situações, começar com um monolito pode ser a melhor decisão, com a possibilidade de migrar para microsserviços à medida que a aplicação cresce e a complexidade exige uma arquitetura mais escalável.
Como é possível perceber, a arquitetura de microsserviços oferece diversos benefícios, mas também impõe desafios técnicos, operacionais e organizacionais significativos. Por isso, sua adoção deve ser feita com cautela e alinhada às reais necessidades do projeto. No entanto, para aplicações complexas, como sistemas web ou soluções SaaS, os microsserviços frequentemente se mostram a escolha mais adequada, especialmente no longo prazo.
As funções init são funções especiais que são executadas antes de qualquer função no código.
Elas são a terceira etapa na ordem de inicialização de um programa em Go, sendo:
Os pacotes importados são inicializados;
As variáveis e constantes globais do pacote são inicializadas;
As funções init são executadas.
Seu uso mais comum é preparar o estado do programa antes da execução principal na main, como por exemplo: verificar se variáveis de configuração estão corretamente definidas, checar a existência de arquivos necessários ou até mesmo criar recursos ausentes.
É possível declarar várias funções init em um mesmo pacote e em pacotes diferentes, desde que todas utilizem exatamente o nome init.
Quando isso ocorre, a ordem de execução delas é a seguinte dependendo do caso:
Em pacotes com dependência entre si
Se o pacote A depende do pacote B, a função init do pacote B será executada antes da função init do pacote A.
O Go garante que todos os pacotes importados sejam completamente inicializados antes que o pacote atual comece sua própria inicialização.
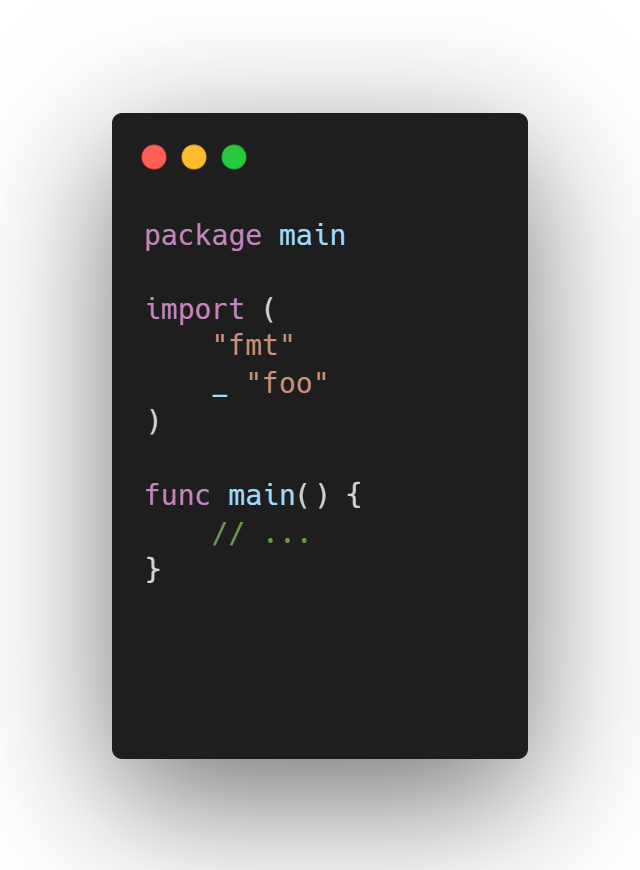
Essa dependência entre pacotes também pode ser forçada usando o identificador em branco, ou blank identifier (_), como no exemplo abaixo que o pacote foo será importado e inicializado, mesmo que não seja utilizado diretamente.
Múltiplas funções init no mesmo arquivo
Quando existem várias funções init no mesmo arquivo, elas são executadas na ordem em que aparecem no código.
Múltiplas funções init em arquivos diferentes do mesmo pacote
Nesse caso, a execução segue a ordem alfabética dos arquivos. Por exemplo, se um pacote contém dois arquivos, a.go e b.go e ambos possuem funções init, a função em a.go será executada antes da função em b.go.
No entanto, não devemos depender da ordem de execução das funções init dentro de um mesmo pacote. Isso pode ser arriscado, pois renomeações de arquivos podem alterar a ordem da execução, impactando o comportamento do programa.
Apesar de úteis, as funções init possuem algumas desvantagens e pontos de atenção que devem ser levados em conta na hora de escolher usá-las ou não:
Elas podem dificultar o controle e tratamento de erros, pois já que não retornam nenhum valor, nem de erro, uma das únicas formas de tratar problemas em sua execução é via panic, que causa a interrupção da aplicação.
Podem complicar a implementação de testes, por exemplo, se uma dependência externa for configurada dentro de init, ela será executada mesmo que não seja necessária para o escopo dos testes unitários. Além de serem executadas antes dos casos de teste, o que pode gerar efeitos colaterais inesperados.
A alteração do valor de variáveis globais dentro da função init pode ser uma má prática em alguns contextos:
Dificulta testes: como o estado global já foi definido automaticamente pela init, é difícil simular diferentes cenários ou redefinir esse estado nos testes.
Aumenta o acoplamento: outras partes do código passam a depender implicitamente do valor dessas variáveis globais, tornando o sistema menos modular.
Reduz previsibilidade: como a inicialização acontece automaticamente e sem controle do desenvolvedor, fica mais difícil entender ou modificar o fluxo de execução do programa.
Afeta reutilização: bibliotecas que dependem de init com variáveis globais são menos reutilizáveis, pois forçam comportamentos no momento da importação.
Em resumo, as funções init são úteis para configurações iniciais, mas seu uso deve ser criterioso, pois podem dificultar testes, tratamento de erros e tornar o código menos previsível.
Referência: HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
Um modelo mental, no contexto de software, é a representação interna que um desenvolvedor constrói para compreender como um sistema ou trecho de código funciona. Ele não é visível, mas sim uma estrutura de raciocínio que permite prever o comportamento do sistema com base no conhecimento adquirido até aquele momento.
Durante a leitura ou escrita de código, o desenvolvedor precisa manter esse modelo atualizado para entender, por exemplo, quais funções interagem entre si, como os dados fluem e quais efeitos colaterais podem ocorrer.
Códigos com boa legibilidade exigem menos esforço cognitivo para manter esses modelos mentais coerentes e atualizados.
Um dos fatores que contribuem para uma boa legibilidade é o alinhamento do código.
Na Golang UK Conference de 2016, Mat Ryer apresentou o conceito de line of sight in code (“linha de visão no código”, em tradução literal). Ele define linha de visão como “uma linha reta ao longo da qual um observador tem visão desobstruída”.
Aplicado ao código, isso significa que uma boa linha de visão não altera o comportamento da função, mas torna mais fácil para outras pessoas entenderem o que está acontecendo.
A ideia é que o leitor consiga acompanhar o fluxo principal de execução olhando para uma única coluna, sem precisar pular entre blocos, interpretar condições ou navegar por estruturas aninhadas.
Uma boa prática é alinhar o caminho feliz da função à esquerda do código. Isso facilita a visualização imediata do fluxo esperado.
O caminho feliz é o fluxo principal de execução de uma função ou sistema, em que tudo ocorre como esperado sem erros, exceções ou desvios.
Na imagem a seguir é possível visualizar um exemplo de caminho feliz:
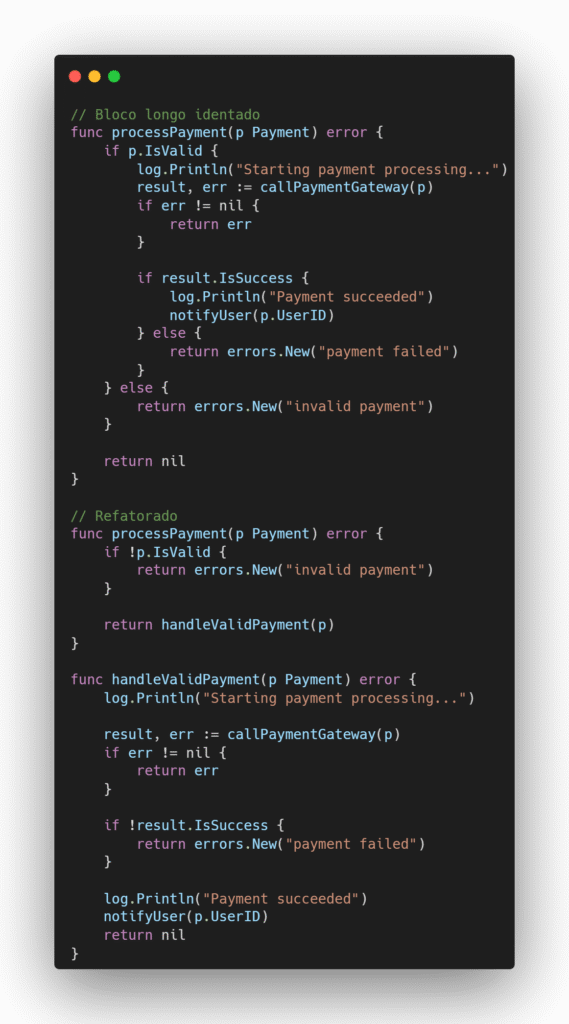
De modo geral, quanto mais níveis de aninhamento uma função possui, mais difícil ela se torna de ler e entender, além de ocultar o caminho feliz, como podemos ver na imagem abaixo:
Retorne o mais cedo possível de uma função. Essa prática melhora a legibilidade porque reduz o aninhamento e mantém o caminho feliz limpo e direto.
Evite usar else para retornar valores, especialmente quando o if já retorna algo. Em vez disso, inverta a condição if (flip the if) e retorne mais cedo, deixando o fluxo principal fora do else.
Coloque o retorno do caminho feliz (o sucesso) como a última linha da função. Isso ajuda a deixar o fluxo principal claro e previsível. Quem lê sabe que, se nada der errado, o sucesso acontece no final.
Separe partes da lógica em funções auxiliares para que as funções principais fiquem curtas, claras e fáceis de entender. Funções muito longas e cheias de detalhes dificultam a leitura e a manutenção.
Se você tem blocos de código muito grandes e indentados (por exemplo, dentro de um if, for ou switch), considere extrair esse bloco para uma nova função. Isso ajuda a manter a função principal mais plana, legível e fácil de seguir, evitando profundidade excessiva e “efeito escada” no código.
Em resumo, cuidar da legibilidade do código é essencial para manter modelos mentais claros. Práticas como alinhar o caminho feliz, evitar aninhamentos profundos e extrair funções tornam o código mais fácil de entender, manter e evoluir.
Referências:
HARSANYI, Teiva. 100 Go mistakes and how to avoid them. Shelter Island: Manning, 2022.
Na arquitetura de software, o monolito é um estilo em que todas as camadas do sistema (como front-end, back-end, lógica de negócio e acesso a dados) estão agrupadas em um único arquivo executável ou componente de deploy.
Apesar de muitas vezes ser mal visto pela comunidade, esse modelo pode trazer diversos benefícios em aplicações pequenas ou em estágios iniciais do projeto, como:
Desenvolvimento simplificado – IDEs e outras ferramentas de desenvolvimento funcionam muito bem com aplicações únicas, tornando o desenvolvimento mais ágil.
Facilidade para mudanças radicais – Como todo o código está no mesmo lugar, é possível alterar APIs, regras de negócio e chamadas ao banco de forma centralizada e consistente.
Testes facilitados – Testes de integração e end-to-end são mais diretos, pois é possível iniciar toda a aplicação, invocar APIs REST e testar as interfaces.
Deploy direto – A publicação é simplificada, geralmente bastando copiar o artefato gerado da compilação para o servidor de aplicação.
Escalabilidade simples – Basta executar múltiplas instâncias da aplicação e utilizar um balanceador de carga (load balancer) para distribuir as requisições.
No entanto, com o crescimento da aplicação, tarefas como desenvolvimento, testes, deploy e escalabilidade tendem a se tornar mais complexas. Essa complexidade, por sua vez, acaba desmotivando os desenvolvedores que precisam lidar com o sistema.
Corrigir bugs ou implementar novas funcionalidades passa a consumir muito tempo. Pior ainda, forma-se uma espiral negativa: o código difícil de entender leva a alterações mal feitas, o que só aumenta a complexidade e os riscos.
Outro problema comum em monolitos que crescem demais é o tempo necessário para realizar o deploy. Como todo o sistema está em uma única base de código, qualquer pequena alteração exige a publicação da aplicação inteira. Se algo der errado nesse processo, há o risco de toda a aplicação ficar indisponível.
Além disso, o monolito pode gerar mais duas complicações importantes. Mesmo sendo simples de escalar horizontalmente, não é possível escalar apenas partes específicas da aplicação, por exemplo, um módulo que recebe um tipo específico de requisição com alto volume. A escalabilidade é sempre feita de forma integral.
A obsolescência tecnológica também é uma preocupação. A linguagem de programação ou framework escolhidos no início do projeto tendem a permanecer até o fim da vida útil do sistema. Isso ocorre porque atualizar toda a base de código pode ser tão trabalhoso que, muitas vezes, é mais viável reescrever o sistema do zero do que atualizá-lo.
Em resumo, o monolito é uma boa escolha no início de um projeto pela sua simplicidade. Porém, com o crescimento da aplicação, surgem desafios que podem comprometer a escalabilidade, manutenção e agilidade. Nesses casos, pode ser necessário repensar a arquitetura para acompanhar a evolução do sistema.
Escopo de variável é o espaço do código onde uma variável pode ser utilizada.
No Go, variáveis declaradas no nível de pacote podem ser usadas dentro de funções do mesmo pacote. Variáveis declaradas dentro de uma função podem ser usadas dentro de blocos de decisão (if) e de repetição (for).
Porém, uma variável de um escopo mais externo (como o nível de pacote ou função) pode ser redeclarada em escopos internos, causando o sombreamento de variável. Isso pode gerar confusão e bugs.
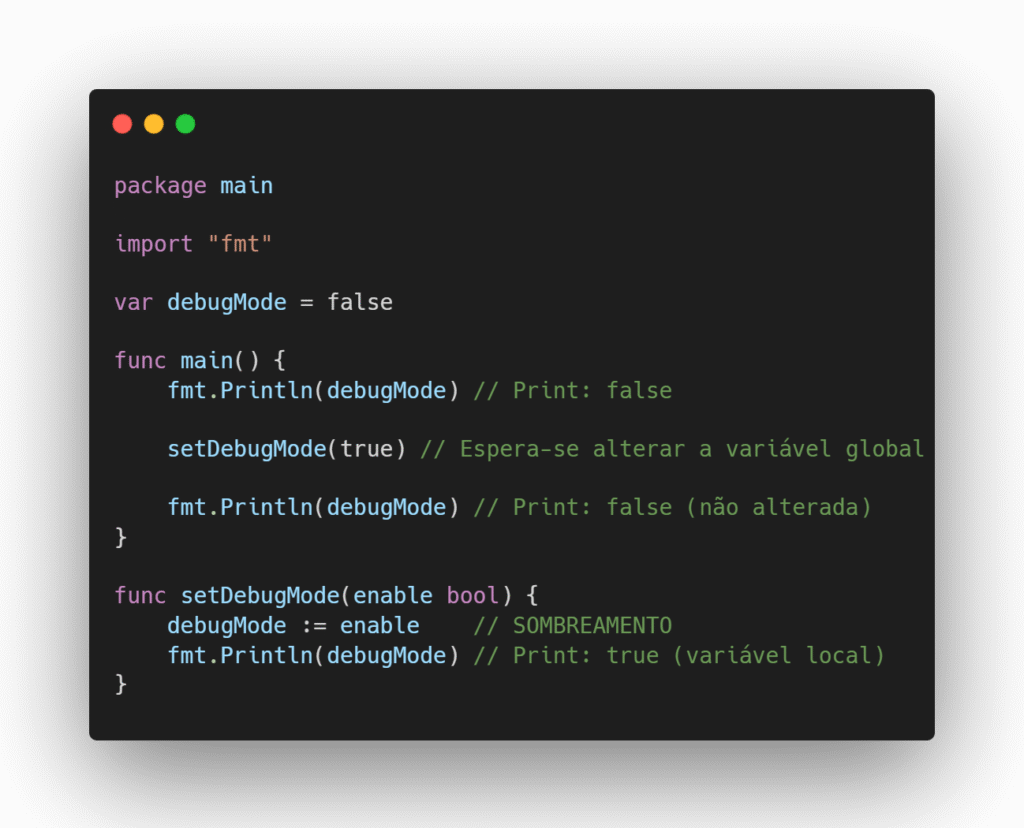
No exemplo abaixo, a variável debugMode é redeclarada dentro da função com o operador de declaração curto (:=), criando uma nova variável local e não alterando a variável do pacote como esperado:
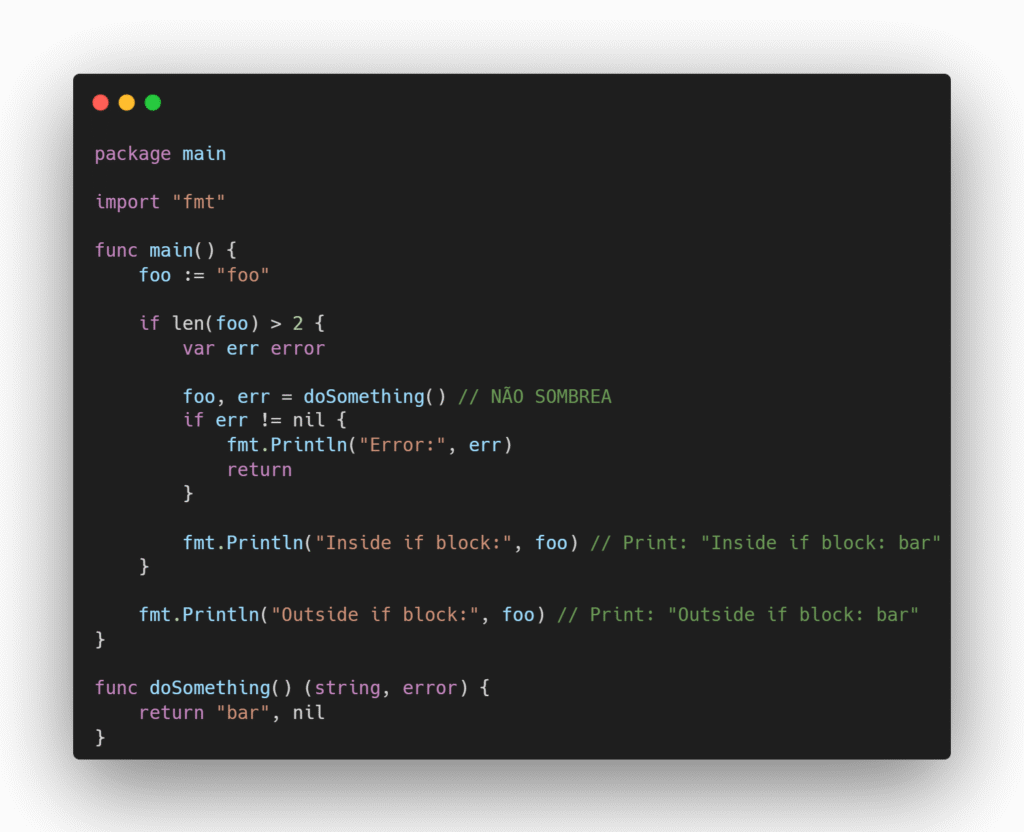
Outro caso é quando usamos o operador de declaração curto (:=) dentro de um bloco if com múltiplos retornos de uma função. No exemplo abaixo, a variável foo é redeclarada dentro do if, sombreando a variável do nível da função e deixando a variável original inalterada:
Para evitar esse problema, a variável de erro deve ser declarada antes do retorno da função e o operador de atribuição simples (=) deve ser utilizado para modificar a variável existente, assim:
Em resumo, o sombreamento acontece quando uma variável é redeclarada em um escopo mais interno, escondendo a original. Para evitar erros, use o operador de atribuição (=) para atribuir valores a variáveis já declaradas e evite redeclarar variáveis com o mesmo nome em escopos próximos.
Um padrão é uma solução reutilizável para um problema que ocorre em um contexto específico.
A ideia surgiu dos projetos de arquitetura e engenharia do mundo real, que vão de grandes soluções, como distribuir o acesso à água em uma cidade, até menores, como definir a posição de uma janela em um quarto para garantir a melhor luminosidade durante o dia. Cada um desses soluciona um problema organizando os objetos físicos dentro de um escopo específico.
Essa abordagem se mostrou útil para a arquitetura de software. Desde os anos 90, desenvolvedores vêm documentando inúmeros padrões de projeto que resolvem problemas arquiteturais, definindo um conjunto de elementos do sistema de forma colaborativa.
Um dos motivos pelos quais os padrões são valiosos é que eles descrevem o contexto em que se aplicam. A ideia é que um padrão oferece uma solução para um contexto específico e pode não funcionar bem em outros contextos. Por exemplo, a solução que resolve o problema do alto número de requisições que o MercadoLivre recebe por dia talvez não seja a melhor para uma startup que está começando agora.
Além de exigir que o contexto do problema seja especificado, um padrão obriga a descrever outros aspectos críticos da solução, como as forças em conflito, as consequências da aplicação e os trade-offs envolvidos.
Um padrão de projeto inclui três características básicas:
Forças: representam os fatores e interesses em conflito que precisam ser considerados ao resolver um problema dentro de um determinado contexto. Essas forças podem entrar em conflito, e é necessário definir quais têm prioridade (dependendo do contexto), pois pode ser impossível atender a todas. Por exemplo, ao projetar um sistema de login, é preciso equilibrar a usabilidade (permitir que o usuário acesse rapidamente) com a segurança (exigir autenticação forte), duas forças que podem entrar em conflito. Ou, de forma mais simples, o código deve ser tanto simples quanto performático, mas um sistema síncrono (mais simples) não é tão performático quanto um assíncrono, que é mais complexo.
Resultado: descreve as consequências da aplicação do padrão, trazendo tanto os benefícios — ou seja, as forças que ele resolve — quanto as desvantagens, que incluem forças não resolvidas e problemas que podem surgir com a aplicação do padrão. Esse resultado fornece uma visão mais completa e equilibrada da solução, permitindo decisões arquiteturais melhores.
Padrões relacionados: como o próprio nome indica, essa característica descreve as relações entre o padrão em questão e outros padrões. Existem cinco tipos principais de relações entre padrões.
Predecessor: é aquele que dá origem ou motiva a aplicação de outro padrão. Por exemplo, o padrão de Microsserviços é predecessor de outros padrões, como Service Discovery e API Gateway.
Sucessor: é aquele que resolve um problema introduzido pelo seu predecessor. Por exemplo, ao adotar o padrão de Microsserviços, surgem desafios como roteamento de requisições e gerenciamento de serviços — problemas que padrões como API Gateway e Service Discovery ajudam a resolver.
Alternativo: é aquele que oferece uma solução alternativa ao padrão escolhido. Por exemplo, o Monolito é uma alternativa aos Microsserviços; deve-se escolher um ou outro.
Generalização: é aquele que oferece uma solução mais ampla e genérica para um tipo de problema. Por exemplo, o padrão Cliente-Servidor é uma generalização de arquiteturas como Microsserviços ou Monolito, pois descreve a ideia básica de separar clientes e servidores, independentemente da complexidade da solução adotada.
Especialização: é aquele que representa uma forma mais específica de outro padrão mais geral — o oposto da generalização.
Além disso, é possível organizar padrões que tratam de questões em uma determinada área de problema em grupos.
Por exemplo, pode-se agrupar os padrões API Gateway e Service Discovery, pois ambos lidam com problemas típicos de sistemas distribuídos.
Compreender e organizar os padrões, suas características e relações permite construir soluções de software mais robustas e adaptáveis, ajudando desenvolvedores e arquitetos a tomar decisões conscientes que equilibram requisitos técnicos e de negócio.